FIELD |
Champ |
|---|---|
| DISK BASIC | |
Syntaxe
| FIELD nmexp,nmexp1 AS var1$ [,nmexp2 AS var2$...] |
Paramètres
| Nom | Description |
|---|---|
| nmexp | Ce paramètre permet d'indiquer un tampon de fichier à accès aléatoire, nmexp=1, 2,...,15. |
| nmexp1 | Ce paramètre permet d'indiquer la longueur du premier champ. |
| var1$ | Ce paramètre permet de définir un nom de variable pour le premier champ. |
| nmexp2 | Ce paramètre permet d'indiquer la longueur du deuxième champ. |
| var2$ | Ce paramètre permet de définir un nom de variable pour le deuxième champ les paires nmexp AS var$ suivantes définissent d'autres champs dans le tampon. |
Description
Avant d'appliquer FIELD sur un tampon, vous devez utiliser une instruction OPEN pour affecter ce tampon à un fichier disque particulier (vous devez utiliser le mode d'accès aléatoire). Utilisez ensuite l'instruction FIELD pour organiser un tampon de fichiers aléatoire afin de pouvoir transmettre des données de BASIC à l'entreposage sur disque et vice-versa.
Chaque tampon de fichier aléatoire a 255 octets pouvant entreposer des données pour le transfert de l'entreposage sur disque vers le BASIC ou du BASIC vers le disque. Cependant, vous avez besoin d'un moyen d'accéder à ce tampon à partir de BASIC afin de pouvoir soit lire les données qu'il contient, soit y placer de nouvelles données. L'instruction FIELD fournit les moyens d'accès.
Vous pouvez utiliser l'instruction FIELD un certain nombre de fois pour "réorganiser" un tampon de fichier. Le FIELD sur un tampon n'efface pas le contenu du tampon ; seuls les moyens d'accès au tampon (les noms des champs) sont modifiés. De plus, deux ou plusieurs noms de champ peuvent faire référence à la même zone du tampon.
Exemples
FIELD 1, 255 AS A$
Cette instruction indique à BASIC d'affecter la totalité du tampon de 255 octets à la variable de chaîne de caractères A$. Si vous affichez maintenant A$, vous verrez le contenu du tampon. Bien sûr, cette valeur n'aurait aucun sens à moins que vous n'ayez utilisé GET pour lire un enregistrement de 255 octets à partir du disque.
Remarque : Toutes les données - à la fois les chaînes de caractères et les nombres - doivent être placées dans le tampon sous forme de chaîne de caractères. Il existe trois paires de fonctions (MKI$/CVI,MKS$/CVS,MKD$/CVD) pour convertir des nombres en chaînes de caractères et vice-versa.
FIELD 3, 16 AS NM$,25 AS AD$,10 AS CY$,2 AS ST$,7 AS ZP$
Les 16 premiers octets du tampon 3 reçoivent le nom de tampon NM$ ; les 25 suivants, AD$ ; les 10 suivants, CY$ ; les 2 suivants, ST$ ; et les 7 suivants, ZP$. Les 195 octets restants du tampon ne sont pas du tout mis en champ.
En savoir plus sur les noms de champs
Les noms de champ, comme NM$, AD$, CY$, ST$ et ZP$, ne sont pas des variables de chaîne de caractères au sens ordinaire. Ils ne consomment pas l'espace de chaîne de caractères disponible pour BASIC.
Au lieu de cela, ils pointent vers le champ tampon que vous avez affecté avec l'instruction FIELD. C'est pourquoi vous pouvez utiliser :
100 FIELD 1,255 AS A$
sans se soucier de savoir si 255 octets d'espace de chaîne de caractères sont disponibles pour A$.
Si vous utilisez un nom de champ tampon sur le côté gauche d'une instruction d'affectation ordinaire, ce nom ne pointera plus vers le champ tampon ; par conséquent, vous ne pourrez pas accéder à ce champ en utilisant le nom de champ précédent.
Par exemple :
A$=B$
annule l'effet de l'instruction FIELD ci-dessus (ligne 100).
Lors d'une entrée aléatoire, l'instruction GET place les données dans le tampon de 255 octets, où elles sont accessibles à l'aide des noms de champ attribués à ce tampon. Pendant la sortie aléatoire, LSET et RSET placent les données dans le tampon, vous pouvez donc mettre (PUT) le contenu du tampon dans un fichier disque.
Souvent, vous ne voudrez pas utiliser une variable factice dans une instruction FIELD pour "passer" une partie du tampon et commencer à la remplir quelque part au milieu. Par exemple :
FIELD 1,15 AS CLIENT$(1),112 AS HIST$(1)
FIELD 1,128 AS DUMMY$,15 AS CLIENT$(2),112 AS HIST$(2)
Dans la deuxième instruction FIELD, DUMMY$ sert à déplacer la position de départ de CLIENT$(2) vers la position 129. De cette manière, deux "sous-enregistrements" identiques sont définis sur le tampon numéro 1. Nous n'utiliserons pas réellement DUMMY$ pour placer données dans la mémoire tampon ou les récupérer à partir de la mémoire tampon.
Le tampon ressemble maintenant à ceci :
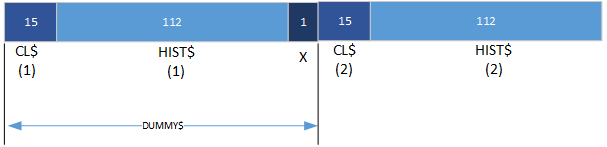
Notez qu'un seul octet (le 128e octet) reste inutilisé dans cette structure de champ.