Recherche en texte intégral (Full-Text Search)
La recherche en texte intégral, nommé Full-Text Search en anglais, dans SQL Server et Azure SQL Database offre la possibilités aux utilisateurs et aux applications d'exécuter des requêtes en texte intégral sur des données basées sur des caractères dans des tables SQL Server. Dans la plupart des cas, nous utiliserons des index en unités d'allocations et sans unité d'allocation pour accélérer une requête, mais ces types d'index ont leurs propres limites et ne peuvent pas être utilisés pour une recherche de texte rapide. Par exemple, un opérateur LIKE conduira SQL Server à analyser l'ensemble de la table afin de récupérer les valeurs correspondant à l'expression à côté de cet opérateur. Cela signifie qu'il ne sera pas rapide dans tous les cas, même si un index est créé pour la colonne considérée.
Le SQL Server propose une réponse à une partie de ce problème avec une fonctionnalité de recherche en texte intégral Full-Text Search. Cette fonctionnalité permet aux utilisateurs et aux applications d'exécuter efficacement des recherches basées sur des caractères en créant un type particulier d'index appelé index de texte intégral. Cet index peut être construit en haut d'une ou plusieurs colonnes pour une table particulière. Ces colonnes peuvent être des types de données suivants :
| Type de données | Description |
|---|---|
| char | Ce type de données permet d'indiquer une chaîne de caractères étant de taille fixe. |
| varchar | Ce type de données permet d'indiquer une chaîne de caractères étant de taille variable. |
| nchar | Ce type de données permet d'indiquer une chaîne de caractères Unicode étant de taille fixe. |
| nvarchar | Ce type de données permet d'indiquer une chaîne de caractères Unicode étant de taille variable. |
| text | Ce type de données permet d'indiquer des données non Unicode de longueur variable dans la page de codes du serveur et avec une longueur de chaîne de caractères maximale de 231-1 (2 147 483 647). |
| ntext | Ce type de données permet d'indiquer des données Unicode de longueur variable avec une longueur de chaîne de caractères maximale de 230 - 1 (1 073 741 823) octets. |
| image | Ce type de données permet d'indiquer des données binaires de longueur variable de 0 à 231-1 (2 147 483 647) octets. |
| xml | Ce type de données permet d'entreposer les données XML. |
| varbinary | Ce type de données permet d'indiquer des données binaires de longueur variable. |
| FILESTREAM | Ce type de données permet aux applications basées sur SQL Server d'entreposer des données non structurées, telles que des documents et des images, sur le système de fichiers. |
La construction et l'utilisation des index de texte intégral (Full-Text Search) sont toujours effectuées dans un contexte linguistique spécifique comme le français, l'anglais, le japonais,...La recherche en texte intégral (Full-Text Search) est une composante optionnelle du moteur de base de données SQL Server. Si vous n'avez pas sélectionné Full-Text Search lors de l'installation de SQL Server, vous devrez l'exécutez à nouveau le programme d'installation de SQL Server pour l'ajouter.
Détection du Full-Text Search
Il est possible de tester la présence du Full-Text Search pour chacune des base de données à l'aide de la requête suivante :
- SELECT name as [DBName], is_fulltext_enabled FROM sys.databases
Si la fonctionnalité est présente, le drapeau is_fulltext_enabled retournera la valeur 1 pour la base de données :
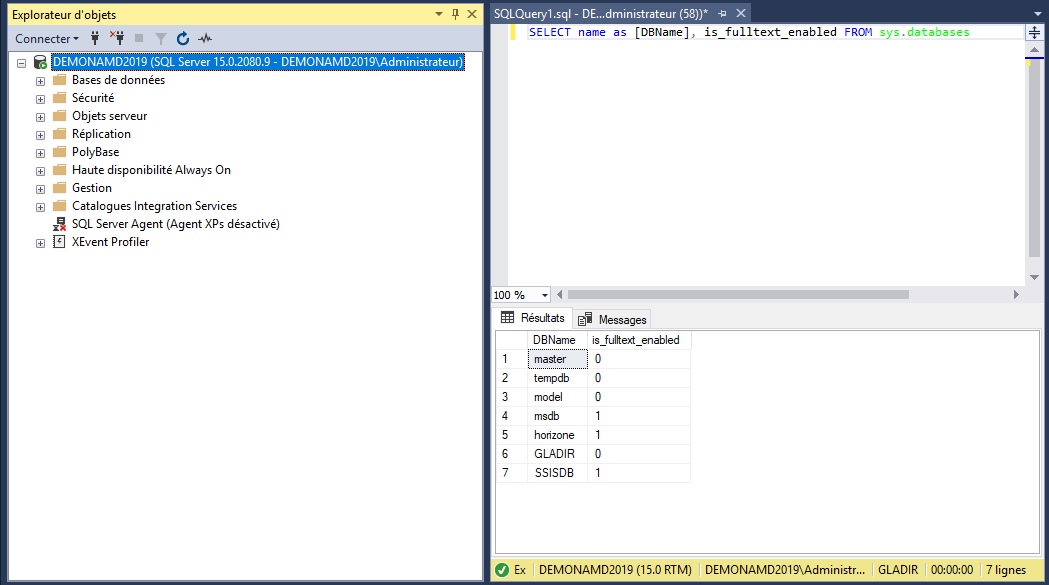
Activation du Full-Text Search
Si après avoir installer la composante «Full-Text and Semantic Extractions for Search», votre base de données n'a pas le Full-Text Search d'activé, vous pouvez exécuter la requête SQL suivante après que vous soyez sur la base de données visés (en utilisant une instruction USE pour la sélectionner) :
- EXEC sp_fulltext_database 'enable'
Désactivation du Full-Text Search
Bien que plus rare, si vous avez besoin de désactiver la fonctionnalité Full-Text Search sur la base de données courante, vous tapez la requête SQL suivante :
- EXEC sp_fulltext_database 'disable'
Concepts
Maintenant que nous savons à quoi sert la fonction de recherche en texte intégral (Full-Text Search), investissons un peu de temps dans la compréhension de son fonctionnement. Notez que, déjà lors de l'installation de SQL Server, nous pouvons dire que cette fonctionnalité est spéciale car le programme d'installation définit un service appelé "fdhost.exe". Ce processus sera appelé ci-après «Hôte du service de filtrage». Il est démarré par un lanceur de service appelé MSSQLFDLauncher pour des raisons de sécurité. Il échangera des données avec le service SQL Server (sqlservr.exe) via la mémoire partagée ou un canal nommé. Le processus fdhost.exe accédera, filtrera et transformera en jeton les données utilisateur afin de créer réellement des index de texte intégral (Full-Text Search). Il est également appelé à analyser les requêtes de texte intégral (Full-Text Search), y compris les coupures de mots et les radicaux.
Cela signifie que l'intégralité de la fonctionnalité de recherche en texte intégral est répartie sur ces deux processus : fdhost.exe et sqlserv.exe et que certains composantes de cette fonctionnalité interagissent les uns avec les autres. Passons en revue ces composantes :
| Composantes | Emplacement | Description |
|---|---|---|
| Tables utilisateur | sqlserv.exe | Tables pour lesquelles un index de texte intégral existe. |
| Collecteur de texte intégral | Dans sqlserv.exe | Un processus léger responsable de la planification et de la conduite de la population d'index afin de le surveiller. |
| Fichiers de dictionnaire des synonymes | sqlserv.exe | Fichiers contenant des synonymes de termes de recherche. |
| StopLists | Dans sqlserv.exe | Objets contenant une liste de mots communs pouvant être ignorés car ils ne sont pas significatifs pour une recherche (par exemple «and», «or», «but»). |
| Processus léger du processeur de requêtes | sqlserv.exe | Processus léger compilant et exécutant les requêtes T-SQL et envoyant la recherche en texte intégral au moteur de texte intégral deux fois : une fois à la compilation et une fois pendant l'exécution de la requête. Les résultats de la requête sont comparés à l'index de texte intégral. |
| Moteur de texte intégral | sqlserv.exe | Peut être considéré comme faisant partie du processeur de requêtes. Il compile et exécute des requêtes en texte intégral et prend en compte les listes de mots vides et les fichiers de dictionnaire de synonymes avant de renvoyer les ensembles de résultats pour ces requêtes. |
| Indexeur de texte intégral | sqlserv.exe | Ce processus léger construit la structure utilisée pour entreposer les jetons d'index. |
| Service de gestion de filtre | sqlserv.exe | Ce processus léger surveille l'état du service fdhost.exe. |
| Processus léger du gestionnaire de protocole | fdhost.exe | Ce processus léger extrait les données de la mémoire pour un traitement ultérieur et accède aux données d'une table utilisateur. |
| Filtres | fdhost.exe | Ils sont spécifiques par type de document et permettent l'extraction de données texte à partir de différents types de données comme varbinary, image ou xml. Ils seront utilisés,
par exemple, afin de supprimer toute mise en forme intégrée sur le texte d'un document Word. Vous pouvez exécuter la requête suivante afin
d'avoir une vue d'ensemble des filtres définis par défaut :
EXEC sp_help_fulltext_system_components 'filter';
|
| Coupe-mots et stemmer | fdhost.exe | Chaque langue a son ensemble de séparateurs de mots. Ces composantes aident à trouver les limites de chaque mot dans une phrase en fonction des règles lexicales de sa langue associée. Ils aident donc à symboliser les phrases. De plus, chaque séparateur de mots est utilisé en paire avec un composante stemmer. Cette composante permet de trouver la racine d'un verbe (sa forme flexionnelle) et de conjuguer le verbe, également sur la base de règles spécifiques à la langue. Par exemple, il considérera toutes ces formes comme étant les mêmes : «writing», «wrote», «writer» sont toutes des formes du mot «write». Les mots identifiés par l'un ou l'autre de ces composantes sont insérés en tant que mots-clefs dans un index de texte intégral. |
Architecture d'un index de texte intégral (Full-Text Index)
Tout d'abord, nous devons savoir que tout index de texte intégral est entreposé dans ce que Microsoft appelle un «catalogue de texte intégral». C'est comme un conteneur pour les index de texte intégral. Pourquoi Microsoft a-t-il défini un conteneur logique pour les index de texte intégral ? Tout simplement parce que ces index sont généralement répartis sur plusieurs tables internes appelées fragments d'index de texte intégral. Ces fragments sont créés lorsque nous insérons ou mettons à jour des enregistrements.
Nous pouvons récupérer des données sur un index de texte intégral à l'aide de vues et de fonctions de gestion dynamique. L'une d'entre elles est la fonction sys.dm_fts_index_keywords_by_document. Il renvoie un ensemble de données avec les colonnes suivantes :
- Une représentation hexadécimale du mot-clef.
- Une représentation lisible par l'homme du mot-clef.
- L'identificateur de la colonne faisant l'objet d'un Index Full-Text.
- L'identificateur du document ou de la ligne à partir duquel le mot-clef courant a été indexé.
- Le nombre de fois où ce mot-clef a été trouvé dans ce document ou cette ligne indiqué par la colonne précédente.
Cela nous permet de dire qu'un index de texte intégral est un "index inversé" car il est généré à partir d'une source de données donnée et cartographie les résultats de cette génération à sa source de données. Nous pouvons également remarquer qu'il calcule des statistiques à la volée sur le nombre d'occurrences. Si nous vérifions la documentation des DMV en texte intégral, nous remarquerons que ces statistiques peuvent être obtenues :
- par document,
- par propriété,
- par mots-clefs.
Cela signifie qu'un index de texte intégral n'est pas vraiment comparable à un index normal. Mais ce n'est pas la seule différence :
- Nous ne pouvons définir qu'un seul index de texte intégral par table alors que nous pouvons en définir plusieurs pour les index normaux.
- L'ajout de données à un index de texte intégral est appelé population. Contrairement aux indices normaux, ces populations ne font pas partie d'une transaction. Cela signifie que même si les données ont été insérées dans une table indexée de texte intégral, ce qui se produit une fois que la transaction qui insère ces données est validée, cela ne signifie pas nécessairement que l'index de texte intégral a été mis à jour. Le remplissage de l'index de texte intégral est désynchronisé.
- Il n'y a pas de regroupement d'index normaux dans un catalogue d'index.
Comment un index de texte intégral (Full-Text Index) est rempli
Comme la population d'index est désynchronisé, qu'est-ce qui indique à SQL Server qu'il est temps de démarrer une population ? Il existe en fait une option s'appelant «Change Tracking» (CHANGE_TRACKING), pouvant être configurée par Full-Text Index et a plusieurs valeurs possibles :
| Valeur | Description |
|---|---|
| AUTO | Demande à SQL Server de suivre les modifications des données d'une table et demande automatiquement le remplissage de l'index. |
| MANUAL | Demande à SQL Server de suivre les modifications apportées aux données d'une table, mais laisse l'utilisateur lui-même demander le remplissage de l'index. Cela signifie qu'il peut s'écouler des heures ou des jours avant que le texte intégral ne soit mis à jour. |
| OFF | Signifie que SQL Server ne suivra pas les modifications de données et que la maintenance de cet index est effectuée totalement manuellement. Sur les systèmes utilisant largement cette fonctionnalité, ce mode pourrait éventuellement nécessiter de grandes fenêtres de maintenance car la population devrait vérifier la lecture de toute la table. |
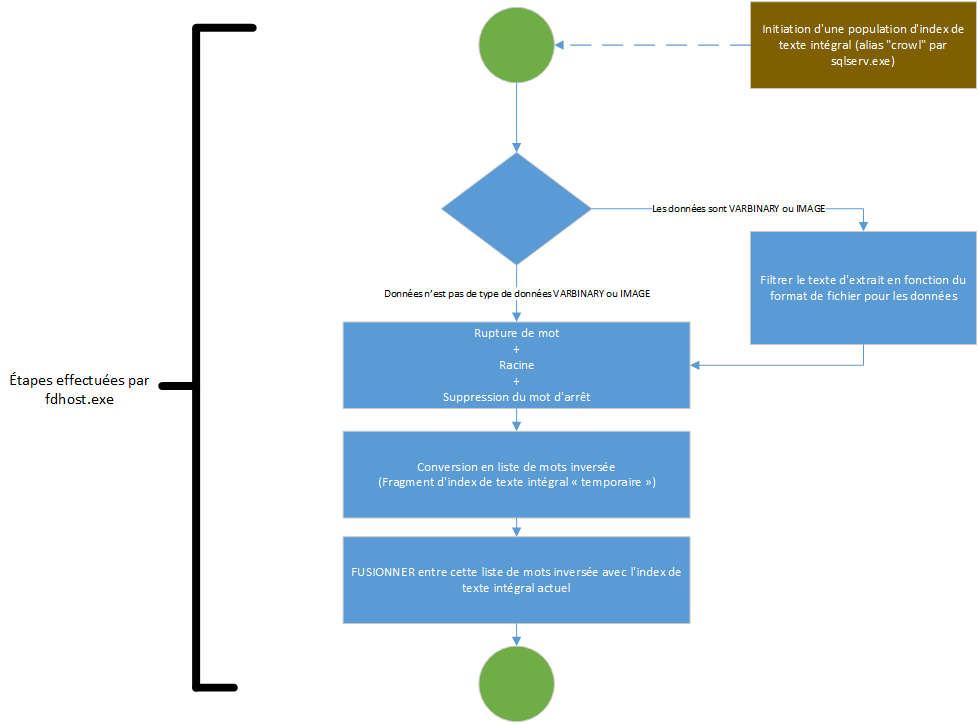
Vous trouverez ci-dessous un diagramme résumant la manière dont un index de texte intégral doit être rempli (pour la première fois ou en fonction de l'activité de l'utilisateur) avec un seul enregistrement nouveau ou mis à jour. Il y a une chose importante à noter : la population d'index est initiée par sqlserv.exe et la population est en fait effectuée par fdhost.exe. Comme indiqué ci-dessus, ce remplissage ne se produira pas à chaque fois qu'un utilisateur créera ou modifiera un enregistrement dans une table indexée en texte intégral. Au lieu de cela, lorsque le suivi des modifications est en mode AUTO, c'est le processus léger Full-Text Gatherer (à l'intérieur de sqlserv.exe) indiquant à fdhost.exe de démarrer le remplissage de l'index. Cela explique en partie pourquoi le processus de remplissage d'index n'est pas synchronisé avec les modifications de données.
Recherche sémantique (Semantic Search)
La recherche sémantique permet d'interroger la signification du document. Par exemple, vous pouvez interroger l'index des phrases clefs pour créer la taxonomie d'une organisation ou d'un corpus de documents. Ou, vous pouvez interroger l'index de similarité des documents pour identifier les CV correspondant à une description de poste.
Gestion d'index de recherche de texte intégral
On peut créer, modifier, supprimer en SQL à l'aide d'une des 3 instructions suivantes :
| Instruction | Description |
|---|---|
| CREATE FULLTEXT INDEX | Cette instruction permet de créer un index de texte plein ou vue d'index dans une base de données de SQL Server. |
| ALTER FULLTEXT INDEX | Cette instruction permet de changer les propriété d'un index de texte plein du SQL Server. |
| DROP FULLTEXT INDEX | Cette instruction permet d'enlever un index de texte plein d'un table spécifié ou d'un vue d'index. |
Vue de gestion dynamique
| Nom de la vue | Description |
|---|---|
| sys.fulltext_index_catalog_usages | Cette vue contient une ligne pour chaque catalogue de texte intégral vers une référence d'index de recherche en texte intégral (Full-Text Search). |
| sys.fulltext_index_columns | Cette vue contient une ligne pour chaque colonne faisant partie d'un index de recherche en texte intégral (Full-Text Search). |
| sys.fulltext_index_fragments | Cette vue contient un index de recherche en texte intégral utilise des tables internes appelées fragments d'index de recherche en texte intégral (Full-Text Search) pour entreposer les données d'index inversées. Cette vue permet d'interroger les métadonnées relatives à ces fragments. Cette vue contient une ligne pour chaque fragment d'index de recherche en texte intégral dans chaque table contenant un index. |
| sys.fulltext_indexes | Cette vue contient une ligne par index de recherche en texte intégral (Full-Text Search) d'un objet tabulaire. |
| sys.dm_fts_index_keywords | Cette vue contient des informations sur le contenu d'un index de recherche en texte intégral (Full-Text Search) pour la table spécifiée. |
| sys.dm_fts_index_keywords_by_document | Cette vue contient des informations sur le contenu de niveau document d'un index de recherche en texte intégral pour la table spécifiée. Un mot clef donné peut apparaître dans plusieurs documents. |
| sys.dm_fts_index_population | Cette vue contient des informations sur les remplissages d'index de texte intégral (Full-Text Search) actuellement en cours. |
Propriétés des colonnes et des tables indexées
Voici les propriétés en texte intégral liées aux colonnes et tables indexées, ainsi que les fonctions Transact-SQL leur étant associées :
| Propriété | Description | Fonction |
|---|---|---|
| FullTextTypeColumn | Cette propriété permet d'indiquer un TYPE COLUMN de la table contenant les informations sur le type de document de la colonne. | COLUMNPROPERTY |
| IsFulltextIndexed | Cette propriété permet d'indiquer si une colonne a été activée pour l'indexation de texte intégral. | COLUMNPROPERTY |
| IsFulltextKey | Cette propriété permet d'indiquer si l'index représente la clef de texte intégral d'une table. | INDEXPROPERTY |
| TableFulltextBackgroundUpdateIndexOn | Cette propriété permet d'indiquer si une table possède une indexation de mise à jour d'arrière-plan de texte intégral. | OBJECTPROPERTYEX |
| TableFulltextCatalogId | Cette propriété permet d'indiquer l'identificateur du catalogue de texte intégral dans lequel résident les données d'indexation de texte intégral de la table. | OBJECTPROPERTYEX |
| TableFulltextChangeTrackingOn | Cette propriété permet d'indiquer si le suivi des modifications de texte intégral est activé pour la table. | OBJECTPROPERTYEX |
| TableFulltextDocsProcessed | Cette propriété permet d'indiquer le nombre de lignes traitées depuis le démarrage de l'indexation de texte intégral. | OBJECTPROPERTYEX |
| TableFulltextFailCount | Cette propriété permet d'indiquer le nombre de lignes que la recherche en texte intégral n'a pas indexées. | OBJECTPROPERTYEX |
| TableFulltextItemCount | Cette propriété permet d'indiquer le nombre de lignes dont l'indexation de texte intégral a réussi. | OBJECTPROPERTYEX |
| TableFulltextKeyColumn | Cette propriété permet d'indiquer l'identificateur de la colonne clef unique de texte intégral. | OBJECTPROPERTYEX |
| TableFullTextMergeStatus | Cette propriété permet d'indiquer s'il s'agit d'une table ayant un index de recherche en texte intégral étant en cours de fusion. | OBJECTPROPERTYEX |
| TableFulltextPendingChanges | Cette propriété permet d'indiquer un nombre d'entrées de suivi des modifications en attente de traitement. | OBJECTPROPERTYEX |
| TableFulltextPopulateStatus | Cette propriété permet d'indiquer l'état de remplissage de la table de texte intégral. | OBJECTPROPERTYEX |
| TableHasActiveFulltextIndex | Cette propriété permet d'indiquer si une table possède un index de recherche en texte intégral actif. | OBJECTPROPERTYEX |