Problèmes de mémoire
Le Turbo Pascal offre plusieurs manières de résoudre les problèmes de mémoire. Pour se faire, vous devez connaître la carte mémoire d'une application Turbo Pascal, les formats de données internes, le gestionnaire de tas et l'accès direct à la mémoire.
La cartographie de la mémoire du Turbo Pascal
Le préfixe de segment de programme (PSP) est une zone de 256 octets créée par DOS lorsque le fichier .EXE est chargé. L'adresse de segment de PSP est entreposée dans la variable pré-déclarée PrefixSeg. Chaque module, comprenant le programme principal et chaque unité, a son propre segment de code. Le programme principal occupe le premier segment de code; les segments de code le suivant sont occupés par les unités (dans l'ordre inverse de la façon dont ils sont répertoriés dans la clause USES), et le dernier segment de code est occupé par l'unité System. La taille d'un segment de code unique ne peut pas dépasser 64 Ko, mais la taille totale du code n'est limitée que par la mémoire disponible.
Le segment de données (adressé via DS) contient toutes les constantes typées suivies de toutes les variables globales. Le registre DS n'est jamais modifié pendant l'exécution du programme. La taille du segment de données ne peut pas dépasser 64 Ko. À l'entrée dans le programme, le registre de segment de pile (SS) et le pointeur de pile (SP) sont chargés de sorte que la paire de registres SS:SP pointe vers le premier octet après le segment de pile. Le registre SS n'est jamais modifié pendant l'exécution du programme, mais SP peut descendre jusqu'à ce qu'il atteigne le bas du segment. La taille du segment de pile ne peut pas dépasser 64 Ko; la taille par défaut est 16 Ko, mais cela peut être changé avec une directive de compilation $M. L'unité standard Overlay utilise le tampon de recouvrement pour entreposer le code de recouvrement. La taille par défaut du tampon de recouvrement correspond à la taille du plus grande recouvrement du programme; si le programme n'a pas de recouvrement, la taille du tampon de recouvrement est égale à zéro. La taille du tampon de recouvrement peut être augmentée par un appel à la routine OvrSetBuf dans l'unité Overlay; dans ce cas, la taille du tas est diminuée en conséquence, en déplaçant HeapOrg vers le haut. La mémoire de tas entrepose des variables dynamiquement, c'est-à-dire que les variables sont allouées via des appels aux procédures standard New et GetMem. Il occupe tout ou partie de la mémoire libre laissée à l'exécution d'un programme. La taille réelle de la mémoire de tas dépend des valeurs de tas minimum et maximum, pouvant être définies avec la directive du compilateur $M. Il est garanti que sa taille est au moins la taille minimale de la mémoire de tas et jamais supérieure à la taille maximale de la mémoire de tas. Si la quantité minimale de mémoire n'est pas disponible, le programme ne s'exécute pas. Le minimum de la mémoire de tas par défaut est de 0 octet et le maximum de la mémoire de tas par défaut est de 640 Ko; cela signifie que par défaut, le tas occupe toute la mémoire restante. Comme vous vous en doutez, le gestionnaire de tas (faisant partie de la bibliothèque d'exécution de Turbo Pascal) gère la mémoire de tas.
Le gestionnaire de la mémoire de tas
La mémoire de tas est une structure de type pile se développant à partir d'une mémoire basse dans le segment de mémoire de tas. Le bas de la mémoire de tas est entreposé dans la variable HeapOrg, et le haut du tas, correspondant au bas de la mémoire libre, est entreposé dans la variable HeapPtr. Chaque fois qu'une variable dynamique est allouée sur la mémoire de tas (via New ou GetMem), le gestionnaire de tas déplace HeapPtr vers le haut de la taille de la variable, empilant en fait les variables dynamiques les unes sur les autres. Le HeapPtr est toujours normalisé après chaque opération, forçant la partie décalée dans la plage $0000 à $000F. La taille maximale d'une seule variable pouvant être allouée sur le tas est de 65 519 octets (correspondant à 10000$ moins 000F$), car chaque variable doit être entièrement contenue dans un seul segment.
Méthodes de disposition
Les variables dynamiques entreposées sur le tas sont supprimées de l'une des deux manières suivantes :
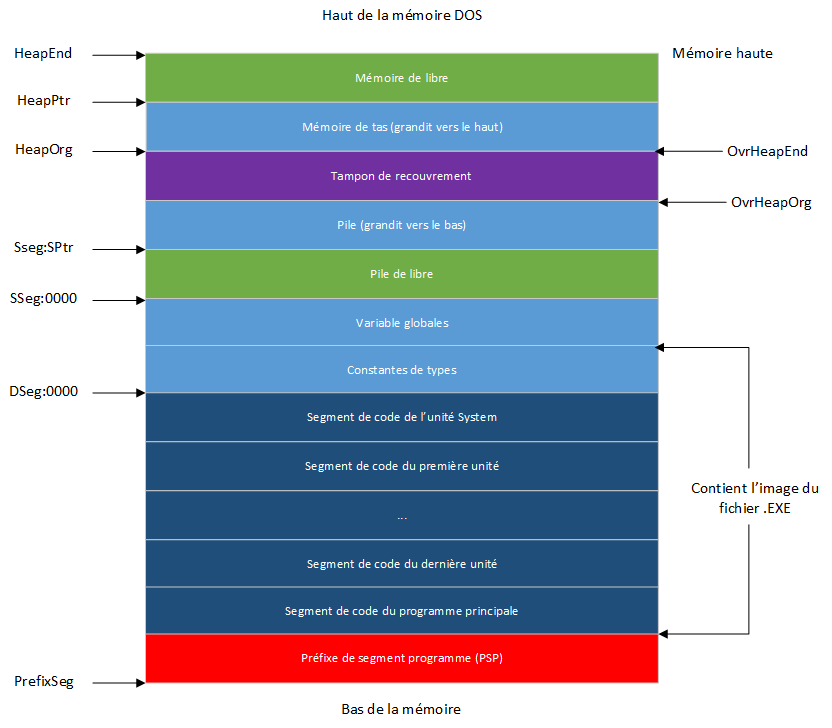
Le schéma le plus simple est celui de Mark et Release; par exemple, si les instructions suivantes sont exécutées :
la disposition de la mémoire de tas ressemblera alors à cette figure :

L'instruction Mark(P) marque l'état de la mémoire de tas juste avant que Ptr3 ne soit alloué (en entreposant le HeapPtr actuel dans P). Si l'instruction Release(P) est exécutée, la disposition de la mémoire de tas devient semblable à celle-ci, éliminant effectivement tous les pointeurs alloués depuis l'appel à Mark :

Pour les applications disposant de pointeurs exactement dans l'ordre inverse d'attribution, les procédures Mark et Release sont très efficaces. Pourtant, la plupart des programmes ont tendance à allouer et à disposer de pointeurs de manière plus aléatoire, nécessitant la technique de gestion plus sophistiquée implémentée par Dispose et FreeMem. Ces procédures permettent à une application de disposer de n'importe quel pointeur à tout moment.
Lorsqu'une variable dynamique n'étant pas la variable la plus élevée du tas est supprimée via Dispose ou FreeMem, le tas devient fragmenté. En supposant que la même séquence d'instructions a été exécutée, puis après avoir exécuté Dispose(Ptr3), un "trou" est créé au milieu de la mémoire tas :
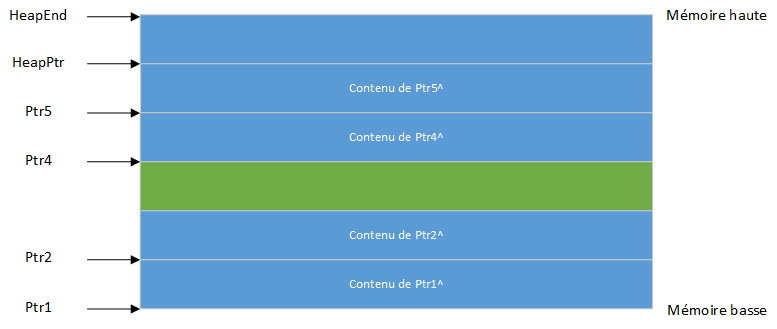
Si New(Ptr3) avait été exécuté maintenant, il occuperait à nouveau la même zone mémoire. D'un autre côté, l'exécution de Dispose(Ptr4) agrandit le bloc libre, car Ptr3 et Ptr4 étaient des blocs voisins :
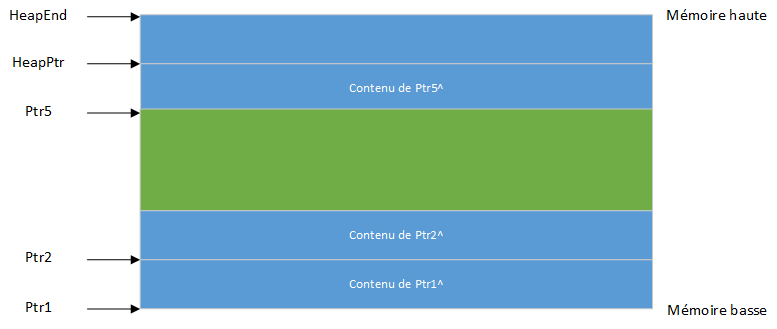
Enfin, l'exécution de Dispose(PtrS) crée d'abord un bloc libre encore plus grand, puis abaisse HeapPtr. Ceci, en effet, libère le bloc libre, car le dernier pointeur valide est maintenant Ptr2 :
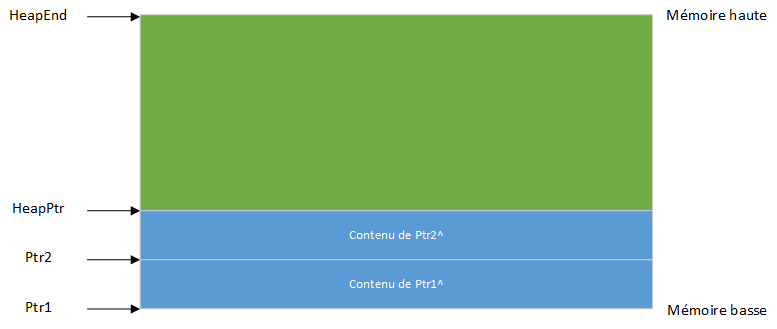
La mémoire de tas est maintenant dans le même état qu'il serait après l'exécution de Release(P), comme au tout début. Les blocs libres créés et détruits au cours du processus ont toutefois été suivis pour une éventuelle réutilisation.
La liste de libre
Les adresses et tailles des blocs libres générés par les opérations Dispose et FreeMem sont conservées sur une liste libre. Chaque fois qu'une variable dynamique est allouée, la liste libre est vérifiée avant que le tas ne soit développé. S'il existe un bloc libre de taille adéquate (il est supérieur ou égal à la taille du bloc demandé), il est utilisé.
La procédure Release efface toujours la liste libre, ce qui fait que le gestionnaire de la mémoire de tas "oublie" tous les blocs libres pouvant exister sous le pointeur de tas. Si vous mélangez des appels à Mark et Release avec des appels à Dispose et FreeMem, vous devez vous assurer qu'aucun de ces blocs libres n'existe.
La variable FreeList dans l'unité System pointe vers le premier bloc libre dans le tas. Ce bloc contient un pointeur vers le prochain bloc libre, contenant un pointeur vers le prochain bloc libre, et ainsi de suite. Le dernier bloc libre contient un pointeur vers le haut de la mémoire de tas (c'est-à-dire vers l'emplacement donné par HeapPtr). S'il n'y a pas de blocs libres sur la liste libre, FreeList sera égal à HeapPtr.
Le format des 8 premiers octets d'un bloc libre est donné par le type TFreeRec comme suit :
Le champ Next pointe vers le prochain bloc libre ou vers le même emplacement que HeapPtr si le bloc est le dernier bloc libre. Le champ Size encode la taille du bloc libre. La valeur dans Size n'est pas une valeur 32 bits normale ; c'est plutôt une valeur de pointeur "normalisée" avec un nombre de paragraphes libres (blocs de 16 octets) dans le mot de poids fort, et un nombre d'octets libres (entre 0 et 15) dans le mot de poids faible. La fonction BlockSize suivante convertit une valeur de champ Size en une valeur normale de type de données LongInt :
Pour garantir qu'il y aura toujours de la place pour un TFreeRec au début d'un bloc libre, le gestionnaire de tas arrondit la taille de chaque bloc alloué par New ou GetMem vers le haut à une limite de 8 octets. Huit octets sont alloués pour les blocs de taille 1..8, 16 octets sont alloués pour les blocs de taille 9..16, et ainsi de suite. Cela peut sembler un gaspillage excessif de mémoire au début, et ce serait le cas si chaque bloc n'avait qu'une taille d'un octet. Cependant, les blocs sont généralement plus grands et la taille relative de l'espace inutilisé est donc moindre.
Le facteur de granularité de 8 octets garantit qu'un certain nombre d'allocations et de désallocations aléatoires de blocs de petites tailles variables, comme cela serait typique pour les enregistrements de ligne de longueur variable dans un programme de traitement de texte, ne fragmentent pas fortement la mémoire de tas. Par exemple, supposons qu'un bloc de 50 octets soit alloué et éliminé, devenant ainsi une entrée sur la liste libre. Le bloc aurait été arrondi à 56 octets (7*8), et une demande ultérieure d'allocation de 49 à 56 octets réutiliserait complètement le bloc, au lieu de laisser 1 à 7 octets d'espace libre (mais très probablement inutilisable), ce qui fragmenterait la mémoire de tas.
La variable HeapError
La variable HeapError vous permet d'installer une fonction d'erreur de tas, étant appelée chaque fois que le gestionnaire de tas ne peut pas terminer une demande d'allocation. Le HeapError est un pointeur pointant vers une fonction avec l'entête suivant :
Notez que la directive FAR force la fonction d'erreur de tas à utiliser le modèle d'appel FAR. La fonction de Heap Error est installée en attribuant son adresse à la variable HeapError :
- HeapError := @HeapFunc;
La fonction d'erreur de tas est appelée chaque fois qu'un appel à New ou GetMem ne peut pas terminer la demande. Le paramètre Size contient la taille du bloc n'ayant pas pu être alloué, et la fonction d'erreur de tas doit tenter de libérer un bloc d'au moins cette taille.
En fonction de son succès, la fonction d'erreur de tas doit renvoyer 0, 1 ou 2. Un retour de 0 indique un échec, provoquant immédiatement une erreur d'exécution. Un retour de 1 indique également un échec, mais au lieu d'une erreur d'exécution, New ou GetMem renvoie un pointeur NIL. Enfin, un retour de 2 indique le succès et provoque une nouvelle tentative (ce qui pourrait également provoquer un autre appel à la fonction de Heap Error).
La fonction d'erreur de la mémoire de tas standard renvoie toujours 0 et provoque une erreur d'exécution chaque fois qu'un appel à New ou GetMem ne peut pas être terminé. Pour de nombreuses applications, cependant, la simple fonction d'erreur de tas suivant est plus appropriée :
Une fois installée, cette fonction oblige New ou GetMem à renvoyer NIL lorsqu'ils ne peuvent pas terminer la demande, au lieu d'abandonner le programme.
Un appel à la fonction de Heap Error avec un paramètre Size de 0 signifie que le gestionnaire de tas vient d'étendre le tas en déplaçant HeapPtr vers le haut. Cela se produit chaque fois qu'il n'y a pas de blocs libres sur la liste libre, ou lorsque tous les blocs libres sont trop petits pour la demande d'allocation. Un tel appel n'indique pas une condition d'erreur, car il y avait encore suffisamment de place pour l'expansion entre HeapPtr et HeapEnd. Au lieu de cela, l'appel indique que la zone inutilisée au-dessus de HeapPtr a rétréci et le gestionnaire de tas ignore la valeur de retour.
Formats de données internes
Le Turbo Pascal traitent des formats de données internes d'entier, de caractère et booléenne, d'énumération,... de façon particulière, voici de quel façon ils sont établies par le compilateur de Turbo Pascal.
Types d'entiers
Le format choisi pour représenter une variable de type entier dépend de ses bornes minimale et maximale :
- Si les deux limites sont comprises dans la plage -128..127 (ShortInt), la variable est entreposée sous la forme d'un octet signé.
- Si les deux limites sont comprises dans la plage 0..255 (Byte), la variable est entreposée sous la forme d'un octet non signé.
- Si les deux limites sont comprises dans la plage -32768..32767 (Integer), la variable est entreposée sous forme de mot signé.
- Si les deux limites sont comprises dans la plage 0..65535 (Word), la variable est entreposée sous forme de mot non signé.
- Sinon, la variable est stockée sous la forme d'un double mot signé (LongInt).
Types de caractères
Un type de données Char, ou une sous-intervalle d'un type Char, est entreposé sous la forme d'un octet non signé.
Types booléens
Un type Boolean est entreposé en tant que Byte, un type ByteBool est entreposé en tant que Byte, un type WordBool est entreposé en tant que Word et un type LongBool est entreposé en tant que LongInt. Un type Boolean peut prendre les valeurs 0 (False) et 1 (True). Les types ByteBool, WordBool et LongBool peuvent prendre la valeur 0 (False) ou différente de zéro (True).
Types énumérés
Un type énuméré est entreposé sous la forme d'un octet non signé si l'énumération a 256 valeurs ou moins ; sinon, il est entreposé en tant que mot non signé.
Types à virgule flottante
Les types à virgule flottante (Real, Single, Double, Extended et Comp) entreposent les représentations binaires d'un signe (+ ou -), d'un exposant et d'une mantisse. Un nombre représenté a la valeur :
| +/-signifiant x 2exposant |
où la mantisse a un seul bit à gauche de la virgule binaire (c'est-à-dire 0 <= mantisse < 2).
Dans les figures suivant, le MSB signifie bit le plus significatif et LSB signifie bit le moins significatif. Les éléments les plus à gauche sont entreposés aux adresses les plus élevées. Par exemple, pour une valeur de type réel, e est entreposé dans le premier octet, fin les cinq octets suivants et s dans le bit de poids fort du dernier octet.
Le type de données Real
Un nombre Real de 6 octets (48 bits) est divisé en trois champs :

La valeur v du nombre est déterminée par les éléments suivants :
|
SI 0 < e ≤ 255 ALORS v ← (-1)S * 2(e-129) * (1.f). FIN SI SI e = 0 ALORS v ← 0. FIN SI |
Le type Real ne peut pas entreposer les dénormalisés, les NaN ou les infinis. Les dénormalisés deviennent nuls lorsqu'ils sont entreposés dans un Real, et les NaN et les infinis produisent une erreur de débordement si une tentative est faite de les entreposer dans un Real.
Type de données Single
Un nombre Single de 4 octets (32 bits) est divisé en trois champs :

|
SI 0 < e < 255 ALORS v ← (-1)5 * 2(e-127) * (1.f). FIN SI SI e = 0 ET f ≠ 0 ALORS v ← (-1)5 * 2(-126) * (0.f). FIN SI SI e = 0 ET f = 0 ALORS v ← (-1)5 * 0. FIN SI SI e = 255 ET f = 0 ALORS v ← (-1)5 * Inf. FIN SI SI e = 255 ET f ≠ 0 ALORS v EST UN NaN. FIN SI |
Type de données Double
Un nombre Double de 8 octets (64 bits) est divisé en trois champs :

La valeur v du nombre est déterminée par les éléments suivants :
|
SI 0 < e < 2047 ALORS v ← (-1)5 * 2(e-1023) * (l.f). FIN SI SI e = 0 ET f ≠ 0 ALORS v = (-1)5 * 2(-1022) * (0.f). FIN SI SI e = 0 ET f = 0 ALORS v = (-1)5 * 0. FIN SI SI e = 2047 ET f = 0 ALORS v = (-1)5 * Inf. FIN SI SI e = 2047 ET f ≠ 0 ALORS v EST UN NaN. FIN SI |
Type de données Extended
Un nombre Extended de l'octet (80 bits) est divisé en quatre champs :
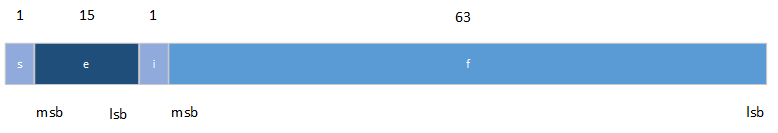
La valeur v du nombre est déterminée par les éléments suivants :
|
SI 0 ≤ e < 32767 ALORS v = (-1)S * 2(e-16383) * (i.f). FIN SI SI e = 32767 ET f = 0 ALORS v = (-1)S * Inf. FIN SI SI e = 32767 ET f ≠ 0 ALORS v EST UN NaN. FIN SI |
Type de données Comp
Un nombre Comp de 8 octets (64 bits) est divisé en deux champs :

La valeur v du nombre est déterminée par les éléments suivants :
|
SI s = 1 ET d = 0 ALORS v EST UN NaN FIN SI |
Sinon, v est la valeur 64 bits du complément à deux.
Type de données Pointer
Un type de données Pointer est entreposé sous forme de deux mots (un mot double), avec la partie de déplacement (Offset) dans le mot de poids faible et la partie segment dans le mot de poids fort. La valeur de pointeur NIL est entreposée sous la forme d'un double mot zéro.
Type de données String
Une chaîne de caractères String occupe autant d'octets que sa longueur maximale plus un. Le premier octet contient la longueur dynamique actuelle de la chaîne de caractères et les octets suivants contiennent les caractères de la chaîne de caractères. L'octet de longueur et les caractères sont considérés comme des valeurs non signées. La longueur maximale de la chaîne de caractères est de 255 caractères plus un octet de longueur (string[255]).
Type de données d'ensemble (Set)
Un ensemble est un tableau de bits, où chaque bit indique si un élément est dans l'ensemble ou non. Le nombre maximum d'éléments dans un ensemble est de 256, donc un ensemble n'occupe jamais plus de 32 octets. Le nombre d'octets occupés par un ensemble particulier est calculé comme suit :
où Min et Max sont les limites inférieure et supérieure du type de base de cet ensemble. Le numéro d'octet d'un élément spécifique E est :
et le numéro du bit dans cet octet est :
- BitNumber := E mod 8
où E désigne la valeur ordinale de l'élément.
Type de données Array
Un tableau est entreposé sous la forme d'une séquence contiguë de variables du type de composante du tableau. Les composantes avec les index les plus bas sont entreposés aux adresses mémoire les plus basses. Un tableau multidimensionnel est entreposé avec la dimension la plus à droite augmentant en premier.
Type de données Record
Les champs d'un enregistrement (RECORD) sont entreposés sous la forme d'une séquence contiguë de variables. Le premier champ est entreposé à l'adresse mémoire la plus basse. Si l'enregistrement contient des parties variantes, alors chaque variante commence à la même adresse mémoire.
Type de données Object
Le format de données interne d'un objet ressemble à celui d'un enregistrement. Les champs d'un objet sont entreposés dans l'ordre de déclaration, sous la forme d'une séquence contiguë de variables. Tous les champs hérités d'un type ancêtre sont entreposés avant les nouveaux champs définis dans le type descendant.
Si un type d'objet définit des méthodes virtuelles, des constructeurs ou des destructeurs, le compilateur alloue un champ supplémentaire dans le type d'objet. Ce champ de 16 bits, appelé champ de table de méthode virtuelle (VMT), est utilisé pour entreposer le déplacement du VMT du type d'objet dans le segment de données. Le champ VMT suit immédiatement les champs ordinaires du type d'objet. Lorsqu'un type d'objet hérite de méthodes virtuelles, de constructeurs ou de destructeurs, il hérite également d'un champ VMT, de sorte qu'un champ supplémentaire n'est pas alloué.
L'initialisation du champ VMT d'une instance est gérée par le(s) constructeur(s) du type d'objet. Un programme n'initialise ou n'accède jamais explicitement au champ VMT. Les exemples suivants illustrent les formats de données internes des types d'objet :
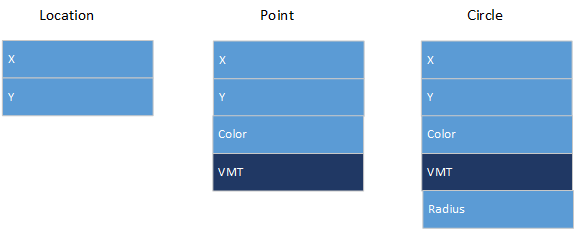
- Type
- PLocation = ^TLocation;
- TLocation=Object
- X,Y:Integer;
- Procedure Init(PX,PY:Integer);
- Function GetXPosition:Integer;
- Function GetYPosition:Integer;
- End;
-
- PPoint = ^TPoint;
- TPoint = Object(TLocation)
- Color:Integer;
- Constructor Init(PX,PY,PColor:Integer);
- Destructor Done;Virtual;
- Procedure Show;Virtual;
- Procedure Hide;Virtual;
- Procedure MoveToPosition(PX,PY:Integer);Virtual;
- End;
-
- PCircle=^TCircle;
- TCircle=Object(TPoint)
- Radius:Integer;
- Constructor Init(PX,PY,PColor,PRadius:Integer);
- Procedure Show;Virtual;
- Procedure Hide;Virtual;
- Procedure Fill;Virtual;
- End;
L'image suivante montre les dispositions des instances de TLocation, TPoint et TCircle ; chaque case correspond à un mot d'entreposage :
Tables de méthodes virtuelles
Chaque type d'objet contenant ou héritant de méthodes virtuelles, de constructeurs ou de destructeurs est associé à un VMT, étant entreposé dans la partie initialisée du segment de données du programme. Il n'y a qu'un seul VMT par type d'objet (pas un par instance), mais deux types d'objets distincts ne partagent jamais un VMT, peu importe à quel point ils semblent être identiques. Les VMT sont construits automatiquement par le compilateur et ne sont jamais directement manipulés par un programme. De même, les pointeurs vers les VMT sont automatiquement entreposés dans les instances de type d'objet par le(s) constructeur(s) du type d'objet et ne sont jamais directement manipulés par un programme.
Le premier mot d'un VMT contient la taille des instances du type d'objet associé ; ces informations sont utilisées par les constructeurs et les destructeurs pour déterminer le nombre d'octets à allouer ou à supprimer, en utilisant la syntaxe étendue des procédures standard New et Dispose.
Le deuxième mot d'un VMT contient la taille négative des instances du type d'objet associé ; ces informations sont utilisées par le mécanisme de validation d'appel de méthode virtuelle pour détecter les objets non initialisés (instances pour lesquelles aucun appel de constructeur n'a été fait), et pour vérifier la cohérence du VMT. Lorsque la validation d'appel virtuel est activée (à l'aide de la directive du compilateur {$R+}, ayant été étendue pour inclure la vérification de méthode virtuelle), le compilateur génère un appel à une routine de validation VMT avant chaque appel virtuel. La routine de validation VMT vérifie que le premier mot du VMT n'est pas nul et que la somme du premier et du deuxième mot est nulle. Si l'une des vérifications échoue, le compilateur génère l'erreur d'exécution 210.
L'activation de la vérification des intervalles et de la vérification des appels de méthode virtuelle ralentit votre programme et le rend un peu plus volumineux, utilisez donc l'état {R+} uniquement lors du débogage et passez à l'état {$R-} pour la version finale du programme.
Le troisième mot d'un VMT contient le déplacement (Offset) du segment de données de la table de méthodes dynamiques (DMT) du type d'objet, ou zéro si le type d'objet n'a pas de méthodes dynamiques.
Le quatrième mot d'un VMT est réservé et contient toujours zéro.
Enfin, à partir du déplacement 8 dans le VMT, se trouve une liste de pointeurs de méthode 32 bits, un par méthode virtuelle dans le type d'objet, dans l'ordre de déclaration. Chaque fente contient l'adresse du point d'entrée de la méthode virtuelle correspondante.
La figure suivante montre les dispositions des VMT des types TPoint et TCircle ; chaque petite case correspond à un mot d'entreposage, et chaque grande case correspond à deux mots d'entreposage.

Remarquez comment TCircle hérite des méthodes Done et MoveTo de TPoint, et comment il remplace les méthodes Show et Hide.
Comme déjà mentionné, les constructeurs d'un type d'objet contiennent un code spécial entreposant le déplacement du VMT du type d'objet dans l'instance en cours d'initialisation. Par exemple, étant donné une instance P de type Pointer et une instance C de type TCircle, un appel à P.Init entrepose automatiquement le déplacement du VMT de TPoint dans le champ VMT de P, et un appel à C.Init entrepose également le déplacement de TCircle du VMT dans le champ VMT de C. Cette initialisation automatique fait partie du code d'entrée d'un constructeur, donc lorsque le contrôle arrive au début de la partie instruction du constructeur, le champ Self de VMT est déjà configuré.
Par conséquent, si le besoin s'en fait sentir, un constructeur peut faire des appels à des méthodes virtuelles.
Tables de méthodes dynamiques
Le VMT d'un type d'objet contient une entrée de quatre octets (un pointeur de méthode) pour chaque méthode virtuelle déclarée dans le type d'objet et l'un de ses ancêtres. Dans les cas où les types ancestraux définissent un grand nombre de méthodes virtuelles, le processus de création de types dérivés peut utiliser beaucoup de mémoire, surtout si de nombreux types dérivés sont créés. Même si les types dérivés ne peuvent remplacer que quelques-unes des méthodes héritées, le VMT de chaque type dérivé contient des pointeurs de méthode pour toutes les méthodes virtuelles héritées, même si elles n'ont pas changé.
Les méthodes dynamiques offrent une alternative dans de telles situations. Au lieu de coder un pointeur pour toutes les méthodes à liaison tardive dans un type d'objet, une table de méthodes dynamiques (DMT) code uniquement les méthodes ayant été remplacées dans le type d'objet. Lorsque les types descendants ne remplacent que quelques-unes des nombreuses méthodes héritées à liaison tardive, le format de table de méthode dynamique utilise moins d'espace que le format utilisé par les VMT. Les deux types d'objet suivants illustrent les formats DMT :
- Type
- TBase=Object
- X:Integer;
- Constructor Init;
- Destructor Done;Virtual;
- Procedure P10;Virtual 10;
- Procedure P20;Virtual 20;
- Procedure P30;Virtual 30;
- Procedure P40;Virtual 40;
- End;
-
- Type
- TDerived=Object(TBase)
- Y:Integer;
- Constructor Init;
- Destructor Done; Virtual;
- Procedure P10; Virtual 10;
- Procedure P30; Virtual 30;
- Procedure P50; Virtual 50;
- End;
Les images suivantes montrent les dispositions des VMT et des DMT de TBase et TDerived. Chaque petite case correspond à un mot d'entreposage, et chaque grande case correspond à deux mots d'entreposage.
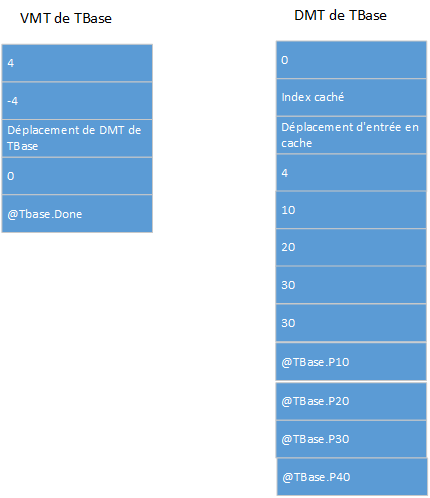
Un type d'objet a un DMT uniquement s'il introduit ou remplace des méthodes dynamiques. Si un type d'objet hérite des méthodes dynamiques, mais n'en remplace aucune ni n'en introduit de nouvelles, il hérite simplement du DMT de son ancêtre. Comme c'est le cas pour les VMT, les DMT sont entreposés dans la partie initialisée du segment de données de l'application.

Le premier mot d'un DMT contient le déplacement de segment de données du DMT parent, ou zéro s'il n'y a pas de DMT parent.
Les deuxième et troisième mots d'un DMT sont utilisés pour mettre en cache les recherches de méthode dynamique.
Le quatrième mot d'un DMT contient le compte d'entrées DMT. Il est immédiatement suivi d'une liste de mots, chacun contenant un index de méthode dynamique, puis suivi d'une liste de pointeurs de méthode correspondants. La longueur de chaque liste est donnée par le nombre d'entrées DMT.
Types de fichier
Les types de fichiers sont représentés sous forme d'enregistrements. Les fichiers typés et les fichiers non typés occupent 128 octets, étant disposés dans l'unité DOS comme suit :
Les fichiers texte occupent 256 octets, répartis comme suit :
- { Enregistrement Textfile }
- Type
- TextBuf=Array[0..127] of Char;
- TextRec=Record
- Handle:Word;
- Mode:Word;
- BufSize:Word;
- Private:Word;
- BufPos:Word;
- BufEnd:Word;
- BufPtr:^TextBuf;
- OpenFunc:Pointer;
- InOutFunc:Pointer;
- FlushFunc:Pointer;
- CloseFunc:Pointer;
- UserData:Array[1..16] of Byte;
- Name:Array[0..79] of Char;
- Buffer:TextBuf;
- End;
Le Handle contient le descripteur du fichier (lorsque le fichier est ouvert) tel que renvoyé par DOS. Le champ Mode peut prendre l'une des valeurs «magique» suivantes :
- Const
- fmClosed=$D7B0;
- fmInput=$D7B1;
- fmOutput=$D7B2;
- fmInOut=$D7B3;
Le fmClosed indique que le fichier est fermé. fmInput et fmOutput indiquent que le fichier est un fichier texte ayant été réinitialisé (fmInput) ou réécrit (fmOutput). Le fmInOut indique que la variable de fichier est un fichier tapé ou non typé ayant été réinitialisé ou réécrit. Toute autre valeur indique que la variable de fichier n'a pas été affectée (et donc non initialisée).
Le champ UserData n'est jamais accessible par Turbo Pascal et est libre pour les routines écrites par l'utilisateur pour entreposer des données. Le Name contient le nom du fichier, étant une séquence de caractères terminée par un caractère nul (#0).
Pour les fichiers typés et les fichiers non typés, RecSize contient la longueur d'enregistrement en octets et le champ Private est inutilisé mais réservé. Pour les fichiers texte, BufPtr est un pointeur vers un tampon d'octets BufSize, BufPos est l'index du prochain caractère dans le tampon à lire ou à écrire, et BufEnd est un nombre de caractères valides dans le tampon. OpenFunc, InOutFunc, FlushFunc et CloseFunc sont des pointeurs vers les routines d'entrée/sortie contrôlant le fichier.
Types de procédure
Un type procédural est entreposé sous forme de mot double, avec la partie offset de la procédure référencée dans le mot de poids faible et la partie segment dans le mot de poids fort.
Accès direct à la mémoire
Le Turbo Pascal implémente trois tableaux prédéfinis, Mem, MemW et MemL, étant utilisés pour accéder directement à la mémoire. Chaque composante de Mem est un octet, chaque composante de MemW est un mot et chaque composante de MemL est un entier LongInt.
Les tableaux Mem utilisent une syntaxe spéciale pour les index : Deux expressions de type entier Word, séparées par deux points, sont utilisées pour spécifier la base du segment et l'offset de l'emplacement mémoire auquel accéder. Voici quelques exemples :
La première instruction entrepose la valeur 7 dans l'octet à $0040:$0049. La deuxième instruction déplace la valeur Word entreposée dans les 2 premiers octets de la variable Vector dans la variable Data. La troisième instruction déplace la valeur LongInt entreposée à $0040:$0054 dans la variable MemLong.
L'exemple suivant permet de demander la taille de la mémoire conventionnelle (00413h à 00414h : La taille mémoire exprimée en Kilo-octets) :
Pour la signification des cellules de mémoire, consulter la page Langage de programmation - Assembleur 80x86 - Référence global de la mémoire des compatibles IBM PC.
Accès direct au port
Pour accéder aux ports de données du processeur 80x86, le Turbo Pascal implémente deux tableaux prédéfinis, Port et PortW. Les deux sont des tableaux à une dimension et chaque élément représente un port de données, dont l'adresse de port correspond à son index. Le type d'index est le type entier Word. Les composantes du tableau Port sont de type Byte et les composantes du tableau PortW sont de type Word.
Lorsqu'une valeur est affectée à une composante de Port ou PortW, la valeur est sortie vers le port sélectionné. Lorsqu'une composante de Port ou PortW est référencé dans une expression, sa valeur est entrée à partir du port sélectionné. L'utilisation des tableaux Port et PortW est limitée à l'affectation et à la référence dans les expressions uniquement ; c'est-à-dire que les composantes de Port et PortW ne peuvent pas être utilisés comme paramètres variables. De plus, les références à l'ensemble du tableau Port ou PortW (référence sans index) ne sont pas autorisées.
L'exemple permet d'attendre qu'une touche d'espacement soit enfoncé :
- Program WaitSpc;
-
- BEGIN
- Repeat Until Port[$60] < $80;
- END.
Pour la signification des ports d'entrée/sortie, consulter la page Langage de programmation - Assembleur 80x86 - Références des ports d'entrée/sortie 80x86.