Réplication avec SQL Server
Les bases de données sont importantes pour tous les types d'entreprises et de nombreuses solutions logicielles utilisent des bases de données pouvant être centralisées et distribuées. La disponibilité des bases de données et la pertinence des données sont essentielles pour les entreprises, faisant de la sauvegarde et de la réplication des bases de données une nécessité. Avec la réplication SQL Server, il est possible de créer une copie identique de votre base de données principale ou de synchroniser les modifications entre plusieurs bases de données et de maintenir la cohérence et l'intégrité des données.
Terminologie utilisée pour la réplication SQL Server
Avant de plonger dans la configuration et la mise en place de la réplication SQL Server, commençons par passer brièvement en revue les principaux termes et les modèles de réplication.
- Articles : Les articles sont les unités de base à répliquer, telles que les tables, les procédures, les fonctions et les vues. Les articles peuvent être mis à l'échelle verticalement ou horizontalement à l'aide de filtres. Plusieurs articles peuvent être créés pour le même objet.
- Une publication Une publication est un ensemble logique d'articles. Il s'agit de l'ensemble final d'entités de la base de données désignée pour la réplication.
- Un filtre Un filtre est un ensemble de conditions pour un article. La réplication SQL Server vous permet d'utiliser des filtres et de sélectionner des entités personnalisées pour la réplication, ce qui, par conséquent, réduit le trafic, la redondance et la quantité de données entreposées dans une réplique de base de données. Par exemple, vous pouvez sélectionner uniquement les tables et les champs les plus critiques à l'aide de filtres et répliquer uniquement ces données.
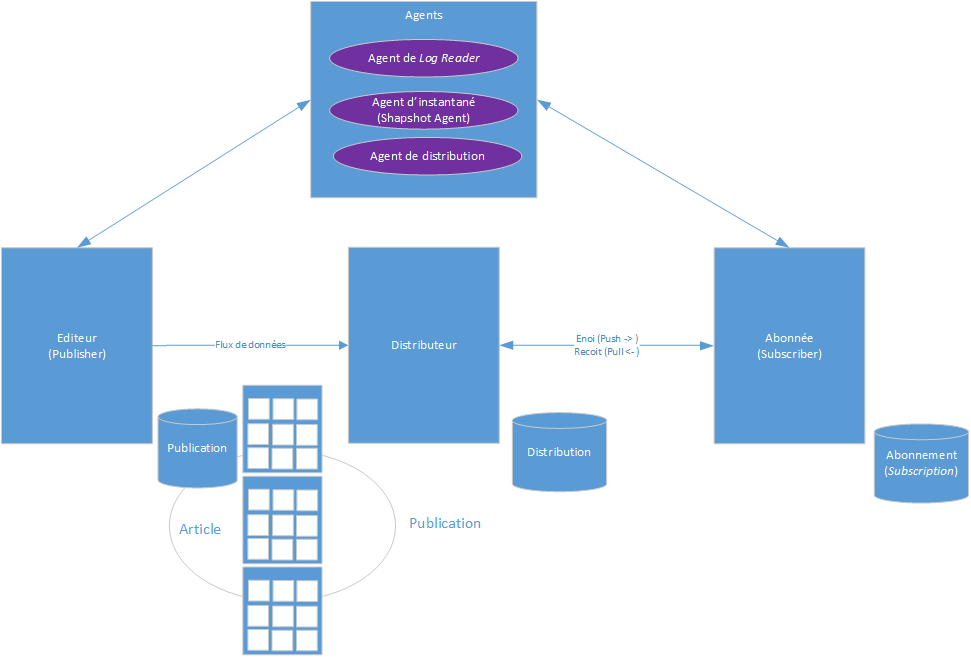
Il y a trois rôles principaux dans la réplication de base de données SQL Server : distributeur, éditeur ou publisher et abonné ou subscriber.
- Un distributeur est une instance de base de données SQL Server configurée pour collecter les transactions des publications et les distribuer aux abonnés. Un distributeur agit comme une base de données pour entreposer les transactions répliquées. Une base de données de distributeurs peut être considérée à la fois comme l'éditeur et le distributeur. Dans le modèle de distributeur local, une seule instance SQL Server exécute à la fois l'éditeur et le distributeur. Un modèle de distributeur distant peut être utilisé lorsque vous souhaitez que les abonnés soient configurés pour utiliser une seule instance SQL Server pour obtenir différentes publications (distribution centralisée). Dans ce modèle, l'éditeur et le distributeur s'exécutent sur des serveurs différents.
- Un éditeur ou publisher est la copie principale de la base de données sur laquelle la publication est configurée, mettant les données à la disposition d'autres serveurs SQL Server configurés pour être utilisés dans le processus de réplication. L'éditeur peut avoir plusieurs publications.
- Un abonné ou subscriber est une base de données recevant les données répliquées d'une publication. Un abonné peut recevoir des données de plusieurs éditeurs et publications. Un modèle à abonné unique est utilisé lorsqu'il n'y a qu'un seul abonné. Un modèle multi-abonnés est utilisé lorsque plusieurs abonnés sont connectés à une seule publication.
Les agents sont des composantes SQL Server pouvant servir de services d'arrière-plan pour le système de gestion de bases de données relationnelles et sont utilisés pour planifier l'exécution automatisée de tâches, telles que la sauvegarde et la réplication de bases de données SQL Server. Il existe cinq types d'agents&ns;: Agent de capture instantanée, Agent de lecture de journal, Agent de distribution, Agent de fusion et Agent de lecture de file d'attente.
L'Abonnement ou Subscriber est une demande de copie d'une publication qui doit être remise à l'Abonné. L'abonnement permet de définir les données de publication qui doivent être reçues, et où et quand ces données seront reçues. Il existe deux types d'abonnement : push et pull.
- Push : les données modifiées sont transmises de force d'un distributeur à la base de données des Abonnés. Aucune demande de l'Abonné n'est nécessaire.
- Pull : les données modifiées effectuées sur l'Editeur sont demandées par un Abonné. L'Agent s'exécute du côté de l'Abonné.
Une base de données d'abonnement est une base de données cible dans le modèle de réplication SQL Server.
Les métadonnées sont les données utilisées pour décrire les entités de la base de données. Il existe un large éventail de fonctions de métadonnées intégrées vous permettant de renvoyer des informations sur l'instance SQL Server, les instances de base de données et les entités de base de données. Dans le modèle à plusieurs éditeurs et à plusieurs abonnés, l'éditeur peut agir en tant qu'abonné sur l'un des serveurs SQL Server. Assurez-vous d'éviter tout conflit de mise à jour potentiel lors de l'utilisation de ce modèle de réplication SQL Server.
Types de réplication SQL Server
La réplication SQL Server est une technologie permettant de copier et de synchroniser des données entre des bases de données de manière continue ou régulière à intervalles planifiés. Quant au sens de réplication, la réplication SQL Server peut être : unidirectionnelle, un-à-plusieurs, bidirectionnelle et plusieurs-à-un. Il existe quatre types de réplication SQL Server : la réplication d'instantané, la réplication transactionnelle, la réplication d'égal à égal et la réplication de fusion.
Réplication d'instantané
La réplication d'instantané est utilisée pour répliquer les données précisément telles qu'elles apparaissent au moment où l'instantané de la base de données a été créé. Ce type de réplication peut être utilisé lorsque les données sont modifiées peu fréquemment ; lorsqu'il n'est pas critique d'avoir une réplique de base de données plus ancienne qu'une base de données master ; ou un grand volume de changements est apporté dans un court laps de temps. Aucun suivi des modifications n'est effectué pour la réplication d'instantané. Par exemple, la réplication d'instantanés peut être utilisée lorsque les taux de change ou les listes de prix sont mis à jour une fois par jour et doivent être distribués d'un serveur principal aux serveurs des succursales.
Réplication transactionnelle
La réplication transactionnelle est la réplication automatisée périodique lorsque les données sont distribuées d'une base de données maître à une réplique de base de données en temps réel (ou quasi-réel). La réplication transactionnelle est plus complexe que la réplication d'instantanés. Non seulement l'état final d'une base de données est répliqué, mais toutes les transactions effectuées sont également répliquées, ce qui permet de surveiller l'intégralité de l'historique des transactions sur la réplique de la base de données. Au début du processus de réplication transactionnelle, un instantané est appliqué à l'Abonné, puis les données sont transférées en continu d'une base de données master vers une réplique de base de données après avoir été modifiées. La réplication transactionnelle est largement utilisée comme réplication unidirectionnelle.
Exemples et cas d'utilisation pour la réplication transactionnelle :
- Création d'un serveur de base de données avec une réplique de base de données pouvant être utilisée pour effectuer un basculement en cas de défaillance d'un serveur de base de données principal.
- Obtenir des rapports sur les opérations effectuées dans les succursales en utilisant plusieurs éditeurs dans les succursales et un abonné dans le bureau principal.
- Les modifications doivent être répliquées dès que possible après leur apparition.
- Les données d'une base de données source sont fréquemment modifiées.
Réplication d'égal à égal
La réplication d'égal à égal est utilisée pour répliquer les données de la base de données vers plusieurs abonnés en même temps. Ce type de réplication SQL Server peut être utilisé lorsque vos serveurs de base de données sont répartis dans le monde entier. Des modifications peuvent être apportées sur n'importe quel serveur de base de données. Les modifications sont propagées à tous les serveurs de base de données. La réplication d'égal à égal peut aider à faire évoluer une application utilisant une base de données. Le principe de fonctionnement principal est basé sur la réplication transactionnelle.
Fusionner la réplication
La réplication de fusion est un type de réplication bidirectionnelle étant généralement utilisé dans les environnements serveur à client pour synchroniser les données entre les serveurs de base de données lorsqu'ils ne peuvent pas être connectés en continu. Lorsque la connexion réseau est établie entre les deux serveurs de base de données, les agents de réplication de fusion détectent les modifications apportées aux deux bases de données et modifient les bases de données pour synchroniser et mettre à jour leur état. La réplication de fusion est similaire à la réplication transactionnelle, mais les données sont répliquées de l'éditeur vers l'abonné et inversement.
Ce type de réplication de base de données est le plus complexe de tous les types de réplication SQL Server et est rarement utilisé. Par exemple, la réplication de fusion peut être utilisée par plusieurs magasins homologues fonctionnant avec un entrepôt partagé. Chaque magasin est autorisé à modifier les informations dans la base de données de l'entrepôt et en même temps, tous les magasins doivent avoir l'état mis à jour de leurs bases de données après l'expédition des marchandises ou la livraison des fournitures à l'entrepôt. La réplication de fusion peut être utilisée dans les cas où les informations mises à jour doivent être disponibles simultanément pour la base de données principale (ou centrale) et les bases de données de branche.
Configuration requise pour la réplication SQL Server
Les ports suivants doivent être ouverts pour le trafic entrant :
| Type | Numéro du port |
|---|---|
| TCP | 1433, 1434, 2383, 2382, 135, 80, 443 |
| UDP | 1434 |
N'oubliez pas de configurer le pare-feu Windows et d'activer les ports appropriés pour le trafic entrant sur chaque hôte avant d'installer SQL Server. Les hôtes assistés à la réplication SQL Server doivent se résoudre les uns les autres par un nom d'hôte.
Avant de configurer la réplication SQL Server, le logiciel suivant doit être installé pour SQL Server :
| Logiciel | Description |
|---|---|
| Cadre d'application .NET | Un ensemble de bibliothèques |
| SQL Server | Le logiciel de serveur de base de données |
| SQL Server Management Studio (SSMS) | Logiciel de gestion des bases de données SQL Server avec l'interface utilisateur graphique (GUI). |
Notez que si vous installez SQL Server 2016 sur la première machine où se trouve la base de données source, la meilleure solution consiste à installer SQL Server 2016 sur la deuxième machine pour que la base de données fonctionne correctement. La réplication ne fonctionnera pas si vous installez SQL Server 2008 sur la deuxième machine. Par exemple, si vous souhaitez configurer la réplication transactionnelle SQL Server, vous pouvez utiliser le deuxième serveur de base de données (où l'Abonné est configuré) d'une version dans deux versions du serveur de base de données source sur lequel l'Éditeur ou publisher est configuré. Plus précisément, si la version Éditeur sur SQL Server est 2016, le Distributeur peut être configuré sur les versions 2016, 2017 et 2019, et l'Abonné peut être configuré sur SQL Server 2012, 2014, 2016, 2017 et 2019.
Configuration de l'environnement
Si vous envisagez de configurer la réplication SQL Server pour la première fois, il est recommandé de vous entraîner dans un environnement de test, par exemple, la configuration de la réplication sur des serveurs SQL exécutés sur des machines virtuelles. Par exemple, on pourrait avoir les 2 hôtes suivants :
| Hôte | Adresse IP | Nom de l'hôte | Identificateur d'instance |
|---|---|---|---|
| 1 | 192.168.0.101 | MSSQL01 | SQLSERVER1 |
| 2 | 192.168.0.102 | MSSQL02 | SQLSERVER2 |
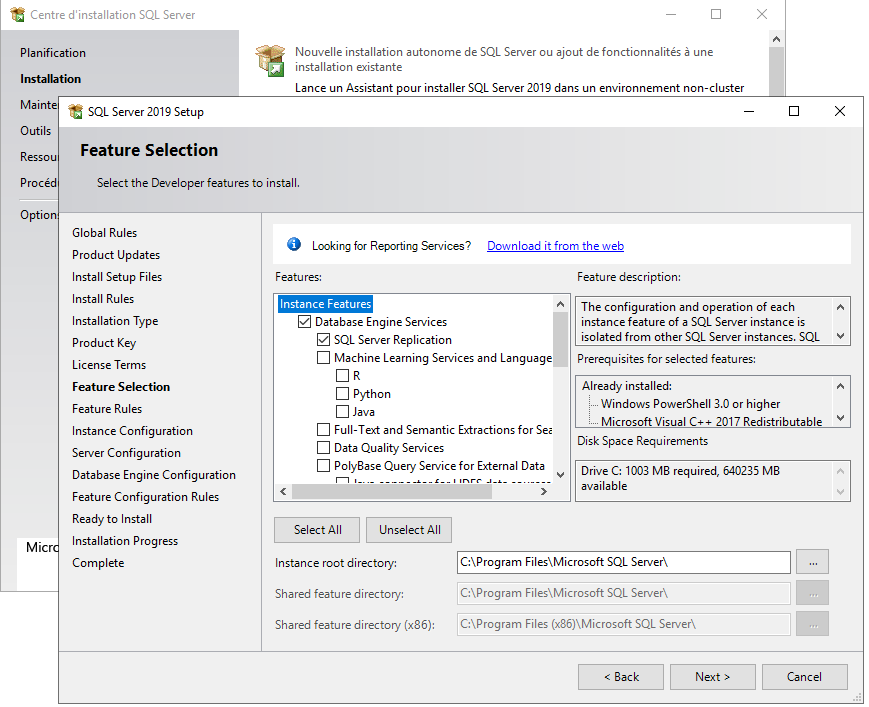
Les deux machines ont le disque C: et le disque D: dans leur configuration de disque. Vous pourriez désactiver temporairement le pare-feu Windows lorsque vous installez SQL Server pour vous entraîner à configurer la réplication SQL Server. Vérifiez que vous avez installé les fonctionnalités requises pour la réplication de SQL Server une fois l'installation de SQL Server terminée. Les services du moteur de base de données, tels que la réplication SQL Server et les (R-Services sous SQL Server 2016), doivent être sélectionnés lors de l'installation de SQL Server. Le chemin d'installation par défaut est utilisé dans cet exemple (C:\Program Files\Microsoft SQL Server).
Déterminer les configuration du Replication de SQL Server avec des requêtes SQL
La Replication du SQL Server entrepose ses informations de configuration dans la table sys.configurations du moteur de SQL Server. Ainsi, il est possible avec la requête SQL suivante d'obtenir la liste des configurations actuellement utilisés par le serveur SQL Server :
- select * from sys.configurations WHERE name LIKE '%repl%';
on obtiendra un résultat ressemblant à ceci :
