Flux de contrôle (séquence, sélection, itération)
Le flux de contrôle désigne l'ordre dans lequel les instructions d'un programme sont exécutées.
Il répond à trois questions fondamentales :
- Dans quel ordre les instructions s'exécutent-elles ?
- Sous quelles conditions certaines instructions sont-elles exécutées ?
- Combien de fois certaines instructions sont-elles répétées ?
Maîtriser le flux de contrôle, c'est maîtriser la logique du programme.
Le flux de contrôle désigne l'ordre dans lequel les instructions d'un programme sont exécutées. Il constitue le squelette logique de tout programme, car il détermine précisément ce qui est exécuté, quand et combien de fois. Sans un flux de contrôle clair et maîtrisé, même un programme simple devient difficile à comprendre, à maintenir et à faire évoluer.
Les trois questions fondamentales du flux de contrôle : Le flux de contrôle répond à trois questions essentielles qui structurent toute logique algorithmique. Premièrement : dans quel ordre les instructions s'exécutent-elles ? C'est la notion de séquence, où les instructions sont exécutées l'une après l'autre. Deuxièmement : sous quelles conditions certaines instructions sont-elles exécutées ? C'est le principe de sélection, qui permet au programme de prendre des décisions. Troisièmement : combien de fois certaines instructions sont-elles répétées ? C'est le rôle de l'itération, qui introduit les boucles et la répétition contrôlée.
La programmation structurée repose entièrement sur la maîtrise du flux de contrôle. En limitant la logique du programme à des constructions bien définies - séquence, sélection et itération - elle permet d'éviter les dérives du code spaghetti, caractérisé par des sauts incontrôlés et une exécution imprévisible. Le flux devient alors linéaire, compréhensible et traçable, ce qui facilite l'analyse du comportement du programme.
Un flux de contrôle bien conçu rend le code prévisible : le développeur sait exactement quelles instructions seront exécutées et dans quel contexte. Cela améliore considérablement la lisibilité, car la logique du programme peut être suivie comme un raisonnement pas à pas. Cette clarté est essentielle pour le débogage, la maintenance et le travail en équipe, où plusieurs développeurs doivent comprendre rapidement la logique existante.
Maîtriser le flux de contrôle, c'est maîtriser la logique du programme. Chaque condition, chaque boucle et chaque séquence doit être pensée pour exprimer clairement l'intention du code. Un bon flux de contrôle ne cherche pas la performance avant tout, mais la compréhension : un programme compréhensible est plus fiable, plus robuste et plus facile à faire évoluer.
Enfin, la maîtrise du flux de contrôle constitue une base indispensable pour aborder des paradigmes plus avancés, comme la programmation orientée objet ou la programmation fonctionnelle. Même dans ces paradigmes, les mêmes principes subsistent : les méthodes, les objets et les fonctions reposent toujours sur des séquences, des conditions et des boucles. Le flux de contrôle reste donc un pilier fondamental de toute structure de code, quel que soit le langage ou le paradigme utilisé.
Le rôle central dans la programmation structurée
La programmation structurée repose sur une idée simple mais puissante :
- Tout programme peut être écrit en utilisant uniquement trois structures de contrôle.
La programmation structurée repose sur une idée à la fois simple et extrêmement puissante : tout programme peut être écrit en utilisant uniquement trois structures de contrôle fondamentales. Cette approche a profondément transformé la manière de concevoir les logiciels, en remplaçant les enchaînements chaotiques d'instructions par une logique claire, hiérarchisée et compréhensible.
Les trois structures de contrôle sur lesquelles repose la programmation structurée sont :
- Séquence
- Sélection
- Itération
Ces structures permettent d'exprimer l'ensemble des comportements possibles d'un programme. Elles constituent un langage logique universel, indépendant du langage de programmation utilisé, que l'on retrouve aussi bien en C, Pascal, Java, Python ou PHP.
Elles remplacent les sauts incontrôlés (goto) et garantissent :
- lisibilité
- fiabilité
- maintenabilité
Avant l'apparition de la programmation structurée, de nombreux programmes utilisaient des sauts incontrôlés, notamment via l'instruction goto. Ces sauts rendaient le flux d'exécution difficile à suivre, conduisant au célèbre code spaghetti, où la logique devient rapidement opaque. En imposant l'utilisation exclusive de la séquence, de la sélection et de l'itération, la programmation structurée élimine ces sauts arbitraires et impose un flux de contrôle maîtrisé.
L'un des principaux bénéfices de ces structures est l'amélioration drastique de la lisibilité. Le code peut être lu de haut en bas, avec des blocs clairement identifiés et des conditions explicites. Chaque structure indique clairement l'intention du développeur : exécuter des instructions dans un ordre précis, faire un choix, ou répéter une action. Cela facilite la compréhension, même pour un développeur qui découvre le code pour la première fois.
Un flux de contrôle structuré rend le programme plus fiable. Les points d'entrée et de sortie sont bien définis, les conditions sont explicites et les boucles sont contrôlées. Cette rigueur réduit les comportements imprévus et limite les erreurs logiques, comme les boucles infinies involontaires ou les branches d'exécution oubliées. Le programme devient ainsi plus robuste face aux cas limites.
Enfin, la programmation structurée améliore considérablement la maintenabilité du code. Un programme organisé autour de ces trois structures est plus facile à modifier, à étendre et à refactoriser. Les développeurs peuvent localiser rapidement les portions de code à ajuster sans risquer de perturber l'ensemble du flux d'exécution. Cette qualité est essentielle pour les projets à long terme, où le code évolue sur plusieurs années.
En résumé, le flux de contrôle occupe un rôle central dans la programmation structurée. En s'appuyant exclusivement sur la séquence, la sélection et l'itération, cette approche remplace les sauts incontrôlés par une logique claire et rigoureuse, garantissant lisibilité, fiabilité et maintenabilité. Ces principes constituent les fondations de toute bonne structure de code et restent valables, même dans les paradigmes modernes comme la programmation orientée objet.
La séquence
Définition et principe fondamental
La séquence est la forme la plus simple et la plus fondamentale de flux de contrôle en programmation structurée. Elle correspond à une exécution linéaire des instructions, dans l'ordre exact où elles apparaissent dans le code, de haut en bas. Chaque instruction est exécutée une seule fois, sans condition ni répétition. La séquence constitue le socle de toute logique algorithmique, sur lequel viennent ensuite s'ajouter les mécanismes de décision et de répétition.
Exemple simple (C)
Ordre d'exécution :
- Initialisation de a
- Initialisation de b
- Calcul de somme
- Affichage
L'ordre d'exécution est strictement déterminé. Le programme commence par initialiser la variable a, puis la variable b. Ensuite, il calcule la variable somme à partir des valeurs précédemment définies, avant d'afficher le résultat. Chaque étape dépend directement de la précédente, ce qui illustre parfaitement le caractère prévisible et déterministe de la séquence.
La séquence est particulièrement appréciée pour sa lisibilité. Le développeur peut lire le code comme une liste d'instructions successives, sans avoir à suivre des chemins alternatifs ou des retours en arrière. Cette simplicité rend la séquence idéale pour les traitements courts, les initialisations, ou les calculs directs. Elle facilite également le débogage, car l'état du programme évolue de manière progressive et compréhensible.
Règles de bonne pratique
- Instructions ordonnées logiquement
- Données initialisées avant usage
- Séquence courte et lisible
Pour exploiter efficacement la séquence, certaines règles doivent être respectées. Les instructions doivent être ordonnées logiquement, afin que chaque opération s'appuie sur des données déjà valides. Les variables et structures doivent toujours être initialisées avant leur utilisation, afin d'éviter les comportements indéfinis. Enfin, les séquences doivent rester courtes et lisibles : une séquence trop longue devient difficile à comprendre et signale souvent la nécessité de découper le code en fonctions.
Limites de la séquence
- Aucune prise de décision
- Aucune répétition
- Peu flexible
Malgré sa simplicité, la séquence présente des limites importantes. Elle ne permet aucune prise de décision : toutes les instructions sont exécutées systématiquement, quelles que soient les conditions. Elle ne permet pas non plus la répétition, ce qui rend impossible le traitement de listes, de collections ou d'entrées multiples. Enfin, sa rigidité la rend peu adaptée aux programmes complexes ou interactifs.
Nécessité de la sélection et de l'itération
Pour dépasser ces limites, la programmation structurée introduit les structures de sélection et d'itération. La sélection permet d'exécuter certaines instructions uniquement sous certaines conditions, tandis que l'itération autorise la répétition contrôlée d'un bloc de code. La séquence reste néanmoins omniprésente : même à l'intérieur des conditions et des boucles, les instructions sont toujours exécutées séquentiellement. Elle demeure ainsi la brique élémentaire de tout flux de contrôle structuré.
La sélection (branchements conditionnels)
Définition et rôle de la sélection
La sélection est une structure fondamentale du flux de contrôle qui permet au programme de prendre des décisions. Elle autorise l'exécution de différents blocs de code en fonction d'une condition, généralement exprimée sous la forme d'une expression logique évaluée à vrai ou faux. Grâce à la sélection, le programme peut s'adapter aux données, aux entrées utilisateur ou à l'état du système, ce qui introduit une logique conditionnelle indispensable à tout programme non trivial.
Structure if / else
La forme la plus courante de sélection est la structure if / else. Dans cet exemple :
La condition age >= 18 est d'abord évaluée. Si elle est vraie, le bloc autoriser() est exécuté ; sinon, le bloc refuser() l'est. Un point essentiel est que un seul bloc est exécuté, ce qui garantit un flux clair et maîtrisé. Cette structure est idéale pour gérer des décisions binaires simples.
- La condition est évaluée
- Un seul bloc est exécuté
Sélections multiples (else if)
Lorsque plusieurs cas doivent être distingués, on utilise des sélections multiples grâce à else if. Par exemple :
Ici, les conditions sont évaluées dans l'ordre, et le premier bloc dont la condition est vraie est exécuté. Cette approche permet de modéliser des règles métier graduelles, comme des barèmes ou des seuils. Toutefois, une chaîne trop longue de else if peut nuire à la lisibilité si elle n'est pas bien structurée.
Structure switch / case
La structure switch / case est une alternative souvent plus lisible lorsque la sélection repose sur une seule variable prenant plusieurs valeurs possibles :
Elle améliore la lisibilité lorsque le nombre de cas est important et que chaque cas est bien distinct. Le mot-clef default permet de gérer les valeurs imprévues. En revanche, le switch est moins flexible que if / else pour les conditions complexes, car il se limite généralement à des comparaisons simples d'égalité.
- Lisible pour de nombreux cas
- Structure claire
- Moins flexible pour conditions complexes
Bonnes pratiques pour la sélection
- Conditions simples et lisibles
- Éviter les imbrications profondes
- Toujours prévoir un cas par défaut
- Commenter les règles métier complexes
Pour conserver un code clair et maintenable, certaines bonnes pratiques doivent être respectées. Les conditions doivent rester simples et lisibles, afin que leur intention soit immédiatement compréhensible. Il est recommandé d'éviter les imbrications profondes de conditions, qui compliquent le suivi du flux d'exécution. Prévoir un cas par défaut est essentiel pour gérer les situations inattendues. Enfin, lorsque les règles métier sont complexes, des commentaires explicatifs ou des fonctions dédiées améliorent grandement la compréhension.
La sélection est un outil essentiel pour introduire de la logique décisionnelle dans un programme structuré. Qu'il s'agisse de if / else, de sélections multiples ou de switch / case, elle permet de contrôler précisément le chemin d'exécution du programme. Bien utilisée, elle améliore la lisibilité, la fiabilité et l'expressivité du code, tout en évitant les pièges du code spaghetti. Elle complète ainsi la séquence et prépare le terrain pour l'itération, troisième pilier du flux de contrôle.
L'itération (boucles)
Définition et rôle de l'itération
L'itération permet de répéter un bloc de code tant qu'une condition est vraie.
L'itération est une structure fondamentale du flux de contrôle qui permet de répéter un bloc de code tant qu'une condition donnée est vérifiée. Elle est indispensable pour traiter des ensembles de données, parcourir des collections, effectuer des calculs répétés ou gérer des entrées utilisateur. Sans les boucles, un programme serait contraint de dupliquer le code, ce qui nuirait à la lisibilité, à la maintenabilité et à la fiabilité.
Boucle for
La boucle for est principalement utilisée lorsque le nombre d'itérations est connu à l'avance. Elle regroupe en une seule ligne l'initialisation de la variable de contrôle, la condition de poursuite et la mise à jour de cette variable :
Cette structure rend la logique de répétition très explicite : on sait immédiatement combien de fois le bloc sera exécuté. La boucle for est donc particulièrement adaptée aux parcours de tableaux, aux comptages ou aux itérations indexées.
Boucle while
La boucle while est utilisée lorsque la répétition dépend d'une condition évaluée avant chaque exécution du bloc :
- while (compteur < 10) {
- compteur++;
- }
Si la condition est fausse dès le départ, le bloc ne s'exécute pas du tout. Cette boucle est idéale pour les situations où le nombre d'itérations n'est pas connu à l'avance, mais dépend de l'évolution d'une variable ou d'un état calculé dynamiquement.
Boucle do / while
La boucle do / while se distingue par le fait que le bloc est exécuté au moins une fois, car la condition est évaluée après l'exécution :
Elle est souvent utilisée pour les scénarios d'interaction utilisateur, où une action doit être effectuée au moins une fois avant de vérifier si elle doit être répétée. Cette structure garantit une première exécution, ce qui la rend complémentaire à la boucle while.
Bonnes pratiques pour les boucles
- Condition claire
- Initialisation correcte
- Mise à jour de la condition
- Prévenir les boucles infinies
Pour écrire des boucles fiables et lisibles, certaines règles sont essentielles. La condition doit être claire et compréhensible, afin que le lecteur sache immédiatement quand la boucle se termine. Les variables de contrôle doivent être correctement initialisées avant l'entrée dans la boucle et mises à jour à chaque itération, afin d'assurer une progression vers la sortie. Enfin, il est crucial de prévenir les boucles infinies, qui surviennent lorsque la condition ne peut jamais devenir fausse.
L'itération est un pilier du flux de contrôle en programmation structurée. Les boucles for, while et do / while offrent des mécanismes complémentaires pour répéter un traitement de manière contrôlée et lisible. Bien conçues, elles permettent de gérer efficacement la répétition, d'éviter la duplication du code et de maintenir une logique claire, tout en s'intégrant harmonieusement avec la séquence et la sélection dans une structure de code cohérente.
Imbrication des structures
L'imbrication des structures consiste à placer une structure de contrôle à l'intérieur d'une autre. Cela peut inclure des boucles dans des boucles, des conditions à l'intérieur de boucles, ou encore des séquences combinées avec des sélections et des itérations. Cette technique permet de gérer des situations complexes où l'exécution d'un bloc dépend à la fois d'une condition et d'une répétition.
Un exemple typique en C illustre cette combinaison : :
Ici, une boucle for parcourt un tableau, tandis qu'une condition if à l'intérieur de la boucle sélectionne uniquement les éléments positifs à additionner. Chaque itération combine donc un mécanisme de répétition et un mécanisme de décision, démontrant la puissance de l'imbrication pour résoudre des problèmes concrets.
L'imbrication permet de modéliser des comportements complexes de manière logique et hiérarchisée. Elle offre la flexibilité nécessaire pour exécuter des traitements conditionnels répétitifs, ou pour gérer des structures de données multidimensionnelles. Sans imbrication, certains algorithmes deviendraient beaucoup plus longs et difficiles à écrire, car il faudrait multiplier les séquences indépendantes ou dupliquer du code.
Malgré sa puissance, l'imbrication doit être utilisée avec modération. Trop de niveaux imbriqués rendent le code difficile à lire, à comprendre et à maintenir. Les bonnes pratiques recommandent de limiter le nombre de niveaux d'imbrication, de documenter clairement chaque bloc imbriqué et, si nécessaire, de extraire des fonctions ou procédures pour clarifier la logique. Par exemple, dans l'exemple précédent, on pourrait créer une fonction estPositif() ou additionnerSiPositif() pour rendre le flux plus lisible.
L'imbrication des structures de contrôle est un outil puissant pour la programmation structurée, permettant de combiner séquence, sélection et itération pour gérer des cas complexes. Cependant, elle doit être utilisée avec prudence : la clarté et la lisibilité du programme restent prioritaires. Bien maîtrisée, l'imbrication permet de créer des programmes logiques, modulaires et robustes, tout en exploitant pleinement le potentiel des flux de contrôle.
Éviter les mauvaises pratiques
- goto
- Conditions trop complexes
- Boucles imbriquées excessives
- Multiples sorties incontrôlées
Dans la programmation structurée, le flux de contrôle doit rester clair, prévisible et maîtrisé. L'utilisation de mauvaises pratiques entraîne un code difficile à comprendre, à maintenir et à déboguer. Certaines habitudes héritées des anciens programmes ou de langages moins structurés, comme les sauts inconditionnels, peuvent générer des erreurs difficiles à détecter et rendre le programme imprévisible.
Le mot-clef goto permet de sauter directement à une autre partie du code. Bien qu'il puisse parfois sembler pratique, son utilisation crée un flux non linéaire qui rend le programme comparable à un « spaghetti » : les instructions s'entremêlent sans hiérarchie, ce qui complique la lecture et la maintenance. La programmation structurée recommande de remplacer goto par des boucles et des conditions clairement définies.
Les conditions imbriquées ou trop longues sont également problématiques. Une condition complexe, avec de multiples opérateurs logiques et niveaux d'imbrication, devient difficile à comprendre et à vérifier. Pour éviter cela, il est préférable de découper les conditions, utiliser des fonctions ou variables intermédiaires et commenter la logique pour rendre le code explicite.
Les boucles imbriquées peuvent rapidement créer une logique opaque et compliquée à suivre. Trop de niveaux imbriqués augmentent le risque d'erreurs, comme des indices mal calculés ou des boucles infinies. Une bonne pratique consiste à limiter l'imbrication, à extraire des blocs de code dans des fonctions ou procédures, et à documenter chaque niveau pour conserver la lisibilité.
Un autre piège consiste à multiplier les points de sortie d'une fonction ou d'une boucle. Avoir plusieurs return ou break disséminés dans un bloc complique la compréhension du flux et peut introduire des effets secondaires imprévus. Il est recommandé d'avoir un point de sortie unique ou de structurer les conditions pour que chaque sortie soit logique et claire.
Éviter ces mauvaises pratiques est essentiel pour maintenir la qualité et la robustesse du code. La programmation structurée privilégie un flux linéaire et hiérarchisé, basé sur séquence, sélection et itération, sans sauts incontrôlés ni complexité excessive. En suivant ces recommandations, le programme devient lisible, maintenable et fiable, préparant ainsi le terrain pour des concepts plus avancés comme la programmation orientée objet.
Visualisation du flux de contrôle
Comprendre le flux de contrôle d'un programme peut parfois être difficile lorsqu'on se limite à lire le code ligne par ligne. La visualisation à l'aide de diagrammes ou de schémas logiques permet de représenter de manière claire et synthétique l'enchaînement des instructions, les décisions conditionnelles et les répétitions. Cela aide à anticiper le comportement du programme, à détecter les erreurs et à optimiser la structure du code.
Diagramme logique (simplifié) :
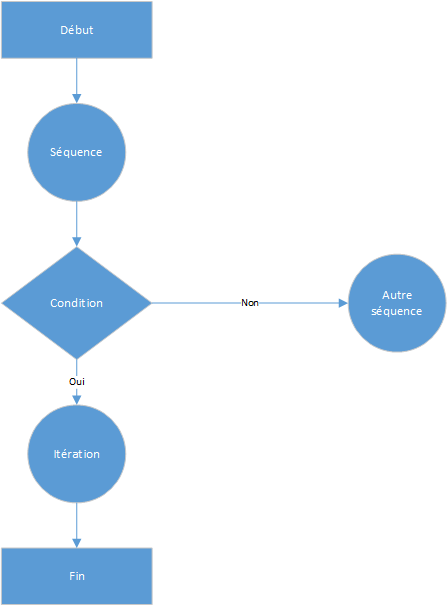
Dans ce diagramme :
- Le programme démarre avec un point d'entrée unique (Début).
- Une séquence d'instructions s'exécute linéairement.
- Une condition est évaluée pour décider quel bloc exécuter ensuite.
- Selon le résultat de la condition, le programme peut suivre une autre séquence ou entrer dans une itération pour répéter certaines opérations.
- Enfin, le programme atteint un point de sortie unique (Fin), garantissant un flux clair et prévisible.
Représenter le flux de contrôle de cette manière permet de :
- Visualiser les chemins possibles d'exécution,
- Identifier rapidement les points de décision et les boucles,
- Détecter les imbrications excessives ou les points de sortie multiples,
- Communiquer la logique du programme à d'autres développeurs de façon simple et compréhensible.
Ces diagrammes sont particulièrement utiles lors de la conception de programmes ou de revues de code. Avant d'écrire le code, le développeur peut tracer un diagramme pour planifier le flux et anticiper les cas particuliers. Pendant la maintenance, il facilite l'identification des zones critiques et des potentielles erreurs logiques.
La visualisation du flux de contrôle est un outil complémentaire à la lecture du code. Elle rend la structure du programme explicite, souligne l'importance de la séquence, de la sélection et de l'itération, et sert de support pour créer un code clair, lisible et robuste. En combinant diagrammes et bonnes pratiques de programmation structurée, le flux devient intuitif et facile à maîtriser.
Exemple complet structuré
L'exemple proposé consiste à compter le nombre de valeurs positives dans un tableau d'entiers. Ce type de problème est idéal pour illustrer l'utilisation combinée des trois structures fondamentales du flux de contrôle : séquence, sélection et itération. Il montre comment organiser un programme simple mais structuré, clair et facilement maintenable.
Problème : compter les nombres positifs
Le programme suit une logique claire et linéaire. Chaque étape est isolée et identifiable, ce qui permet de suivre facilement le flux d'exécution.
Analyse par structure de contrôle :
- Séquence : initialisation : La première ligne int compteur = 0; initialise la variable qui servira à compter les nombres positifs. Cette instruction est exécutée une seule fois, de manière linéaire, et constitue une séquence simple et lisible.
- Itération : parcours du tableau : La boucle for parcourt le tableau entier, itérant sur chaque élément. Ici, le nombre d'itérations est déterminé par la taille du tableau, illustrant l'usage classique de l'itération pour traiter des collections de données.
- Sélection : test de chaque valeur : À l'intérieur de la boucle, la condition if (tab[i] > 0) vérifie si la valeur actuelle est positive. Si c'est le cas, le compteur est incrémenté. Cette structure de sélection introduit une logique décisionnelle simple et permet de filtrer uniquement les valeurs pertinentes.
L'exemple montre comment combiner les trois piliers du flux de contrôle tout en gardant le programme lisible et modulaire. Chaque instruction a un rôle clair, ce qui facilite le débogage et la maintenance. De plus, la structure peut être réutilisée ou adaptée facilement pour des variantes du problème, comme compter les nombres négatifs ou supérieurs à un seuil donné.
Ce petit programme illustre parfaitement la puissance de la programmation structurée. En utilisant séquence, sélection et itération de manière cohérente, le code reste prévisible, lisible et efficace. Il démontre également que même des problèmes simples bénéficient grandement d'une organisation claire et de bonnes pratiques de flux de contrôle.
Flux de contrôle et lisibilité
Un bon flux de contrôle :
- se lit comme une histoire
- suit une logique métier claire
- est facile à tester et à déboguer
Le flux de contrôle d'un programme détermine l'ordre dans lequel les instructions s'exécutent. Lorsque ce flux est bien structuré, il se lit presque comme une histoire, où chaque action suit naturellement la précédente. Cette lisibilité est essentielle pour que le programmeur, ou tout collaborateur, puisse comprendre rapidement le fonctionnement du code, anticiper ses effets et identifier les éventuelles erreurs.
Un flux de contrôle clair reflète la logique métier que le programme est censé implémenter. Les séquences doivent correspondre à des étapes cohérentes, les conditions doivent représenter des décisions explicites et les boucles doivent traduire des répétitions logiques. Par exemple, dans un programme de gestion de comptes, le flux devrait suivre les étapes naturelles : lecture des données, calcul des soldes, application des règles de gestion et affichage des résultats. Chaque structure de contrôle devient ainsi intuitive et alignée avec le problème à résoudre.
Un flux de contrôle bien organisé facilite également le test et le débogage. Les erreurs sont plus facilement localisables si chaque séquence, sélection ou itération a un rôle précis et identifiable. De plus, les tests unitaires peuvent être appliqués sur des fonctions ou procédures isolées, car le flux logique est prévisible et modulable. À l'inverse, un flux chaotique, avec des sauts incontrôlés ou des boucles imbriquées excessives, rend le débogage laborieux et augmente le risque d'erreurs cachées.
Pour maximiser la lisibilité, il est recommandé de :
- garder les séquences courtes et cohérentes,
- limiter l'imbrication des conditions et des boucles,
- utiliser des noms explicites pour les fonctions et variables,
- commenter les parties complexes du flux de contrôle.
Ces pratiques assurent que le programme reste intuitif, facile à comprendre et à maintenir, tout en respectant les principes de la programmation structurée.
En résumé, un flux de contrôle clair est la clef pour écrire un code lisible, fiable et maintenable. Il transforme le programme en une histoire cohérente, reflétant fidèlement la logique métier et facilitant le test et le débogage. La maîtrise de la séquence, de la sélection et de l'itération, combinée à une organisation réfléchie, garantit que le programme reste compréhensible pour tout développeur et résistant aux erreurs.
Lien avec les autres règles structurées
Cette partie est étroitement lié à :
Le flux de contrôle s'appuie en premier lieu sur le code séquentiel, constituant la base de toute exécution de programme. La séquence définit l'ordre naturel des instructions, tandis que la sélection et l'itération viennent enrichir ce flux en introduisant des décisions et des répétitions. Sans une séquence claire et maîtrisée, les structures conditionnelles et les boucles perdent leur sens. Le flux de contrôle ne remplace donc pas le code séquentiel, il le structure et l'organise de manière plus expressive.
Le découpage en fonctions et procédures est étroitement lié au flux de contrôle. Chaque fonction représente un sous-flux logique clairement délimité, avec un point d'entrée et un point de sortie bien définis. Le programme principal devient alors une orchestration de flux simples, lisibles et hiérarchisés. Cette approche réduit la complexité globale, car le développeur peut raisonner sur des blocs cohérents plutôt que sur un enchaînement massif d'instructions imbriquées.
La gestion des données influence directement la clarté du flux de contrôle. Des données bien structurées, correctement typées et à portée maîtrisée permettent d'écrire des conditions plus simples et des boucles plus sûres. À l'inverse, une mauvaise organisation des données entraîne des tests complexes, des traitements dispersés et un flux de contrôle difficile à suivre. Ainsi, un bon flux repose autant sur la structure du code que sur la qualité des données manipulées.
Le flux de contrôle joue également un rôle central dans la modularité du programme. En combinant séquence, sélection et itération à l'intérieur de modules bien définis, il devient possible de construire des composants indépendants et réutilisables. Chaque module possède son propre flux interne, tout en s'intégrant harmonieusement dans le flux global du programme. Cette organisation favorise l'évolution du code, la maintenance à long terme et la réutilisation dans d'autres projets.
En définitive, le flux de contrôle agit comme un liant entre toutes les règles de la programmation structurée. Il relie le code séquentiel, le découpage fonctionnel, la gestion des données et la modularité en une architecture cohérente. Maîtriser le flux de contrôle, c'est donc comprendre comment ces règles interagissent pour produire un programme clair, robuste et évolutif, fidèle aux principes fondamentaux de la programmation structurée.
Transition vers la POO
Les mêmes structures existent en POO :
- Méthodes séquentielles
- Conditions métier
- Boucles de traitement
Le passage de la programmation procédurale à la programmation orientée objet (POO) ne remet pas en cause les fondements du flux de contrôle. Les trois structures universelles - séquence, sélection et itération - restent pleinement valables et constituent toujours la base de l'exécution du code. Qu'il s'agisse d'une fonction procédurale ou d'une méthode orientée objet, les instructions s'exécutent dans un ordre déterminé, selon des conditions précises et éventuellement de manière répétée.
En POO, la séquence se retrouve naturellement à l'intérieur des méthodes. Une méthode contient généralement une suite d'instructions exécutées de manière linéaire, exactement comme dans une fonction procédurale. La différence majeure réside dans le contexte d'exécution : la méthode agit sur l'état interne de l'objet, à travers ses attributs. Le flux séquentiel devient ainsi encapsulé, ce qui renforce la cohérence entre les données et les traitements.
Les structures de sélection (if, else, switch) sont largement utilisées en POO pour implémenter des règles métier. Les décisions ne sont plus seulement basées sur des variables globales ou des paramètres isolés, mais sur l'état de l'objet et parfois sur les interactions entre plusieurs objets. Cette approche rend les conditions plus expressives et mieux localisées, car chaque classe est responsable de ses propres choix de comportement.
Les boucles conservent un rôle central en POO, notamment pour parcourir des collections d'objets ou répéter des traitements sur des ensembles de données. Les itérations sont souvent intégrées dans des méthodes spécialisées, ce qui permet de masquer la complexité du parcours et d'exposer une interface claire. Le flux itératif devient alors un détail d'implémentation, invisible pour le reste du programme.
La différence essentielle entre le procédural et la POO réside dans l'encapsulation du flux de contrôle. En programmation orientée objet, le flux n'est plus principalement dirigé par une fonction centrale, mais réparti entre des objets autonomes qui collaborent entre eux. Chaque objet contrôle son propre flux interne, ce qui améliore la lisibilité globale, la maintenabilité et l'évolutivité du système.
Ainsi, la transition vers la POO doit être comprise comme une évolution naturelle de la programmation structurée plutôt qu'une rupture. Les mêmes mécanismes de contrôle sont conservés, mais intégrés dans une architecture plus riche et plus expressive. La maîtrise du flux de contrôle en programmation procédurale constitue donc une base indispensable pour aborder efficacement la programmation orientée objet.
Résumé
| Structure | Rôle |
|---|---|
| Séquence | Ordre naturel |
| Sélection | Décision |
| Itération | Répétition |
Ces trois structures suffisent à écrire n'importe quel programme correctement structuré.
La maîtrise du flux de contrôle repose sur la compréhension et l'utilisation cohérente de trois structures fondamentales : la séquence, la sélection et l'itération. Ces structures constituent le socle de la programmation structurée et définissent la manière dont un programme s'exécute pas à pas. Elles permettent de transformer un problème abstrait en une logique exécutable claire, prévisible et maintenable.
La séquence représente l'ordre naturel d'exécution des instructions. Elle impose une progression linéaire du programme, où chaque instruction est exécutée après la précédente. Cette structure est essentielle pour organiser les traitements de base, garantir que les données sont initialisées avant utilisation et rendre le code facile à lire. Sans séquence claire, même les programmes les plus simples deviennent confus et sujets aux erreurs.
La sélection introduit la capacité de prise de décision. Grâce aux conditions, le programme peut adapter son comportement en fonction de l'état des données ou du contexte d'exécution. La sélection permet d'exprimer les règles métier, de gérer les cas particuliers et d'orienter le flux d'exécution vers le bon chemin. Bien utilisée, elle rend le code expressif et logique ; mal maîtrisée, elle peut rapidement nuire à la lisibilité par des imbrications excessives.
L'itération, enfin, apporte la répétition contrôlée des instructions. Elle évite la duplication du code et permet de traiter des ensembles de données de manière systématique. Les boucles structurées assurent un contrôle précis du nombre de répétitions et des conditions d'arrêt, ce qui contribue à la fiabilité du programme. Une itération bien conçue est à la fois performante, claire et facile à maintenir.
En combinant intelligemment séquence, sélection et itération, il est possible de construire n'importe quelle logique algorithmique, quelle que soit sa complexité. Ces trois structures suffisent à écrire tout programme correctement structuré, sans recourir à des mécanismes de contrôle dangereux ou obscurs comme les sauts inconditionnels. Elles forment ainsi un langage universel de la logique informatique, commun à tous les paradigmes et à tous les langages de programmation.
Conclusion
Le flux de contrôle est la charpente logique du code.
Sans maîtrise de la séquence, de la sélection et de l'itération, aucun programme ne peut être :
- fiable
- lisible
- maintenable